How to avoid Go gotchas
TL;DR by learning internals
a gotcha is a valid construct in a system, program or programming language that works as documented but is counter-intuitive and almost invites mistakes because it is both easy to invoke and unexpected or unreasonable in its outcome (source: wikipedia)
Go programming language has some gotchas and there is a number of good articles explaining them. I find those articles very important, especially for the newcomers in Go, as I see people run into those gotchas every now and then.
But one question was bugging me for a long time - why I never ran into most of these gotchas? Seriously, most famous of them, like “nil interface” confusion or “slice append” issue was never an issue for me. I somehow avoided those problems from the very first days of working with Go. Why is it so?
And the answer was actually simple. It turned out that I was lucky enough to read some articles about internal representations of Go data structures and learn some basics of how things work internally in Go. And that knowledge was enough to build intuition about Go and avoid those gotchas.
Remember, “gotchas are .. valid constructs .. but is counter-intuitive”? That is it. You have only two options:
- “fix” the language
- fix the intuition
Second is actually would be better seen as build the intuition. Once you have a clear mental image of how slices or interfaces work under the hood, it’s almost impossible to run into those mistakes.
So, it worked for me and probably will work for others. That’s why I decided to gather that basic knowledge of some Go internals in this post and help people to build the intuition about an in-memory representation of different things.
Let’s start from basic understanding how things are represented in memory. Quick overview of what we’re going to learn:
Pointers
Go is pretty close to the hardware, actually. When you create a 64-bit integer (int64) variable you know exactly how much memory it takes, and you can use unsafe.Sizeof() for calculating the size of any other type.
I often use visualization of memory blocks to “see” the sizes of the variables, arrays, and data structures. Visual representation gives you an easy way to get the intuition about types and often helps to reason about behavior and performance.
For the warm-up let’s visualize most basic types in Go:
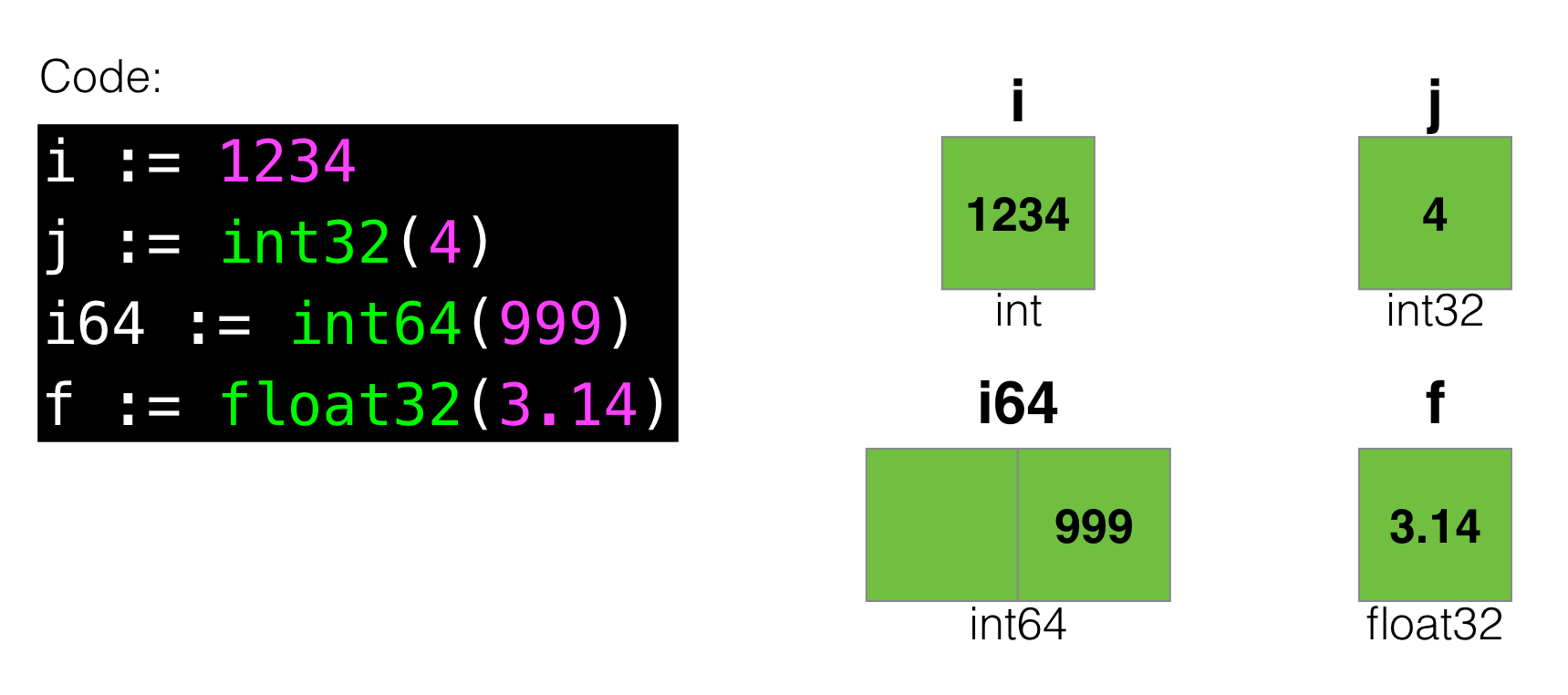 Assuming you’re on the 32-bit machine (which is probably false nowadays), you can see that int64 takes twice as much memory as int.
Assuming you’re on the 32-bit machine (which is probably false nowadays), you can see that int64 takes twice as much memory as int.
A bit more complicated an internal representation of pointers - in fact, it’s the one block in memory, which contains a memory address to some other region in memory, where actual data is stored. When you hear the fancy word “dereferencing a pointer” it actually means “getting to the actual memory blocks by an address stored in the pointer variable”. You may imagine it like this:
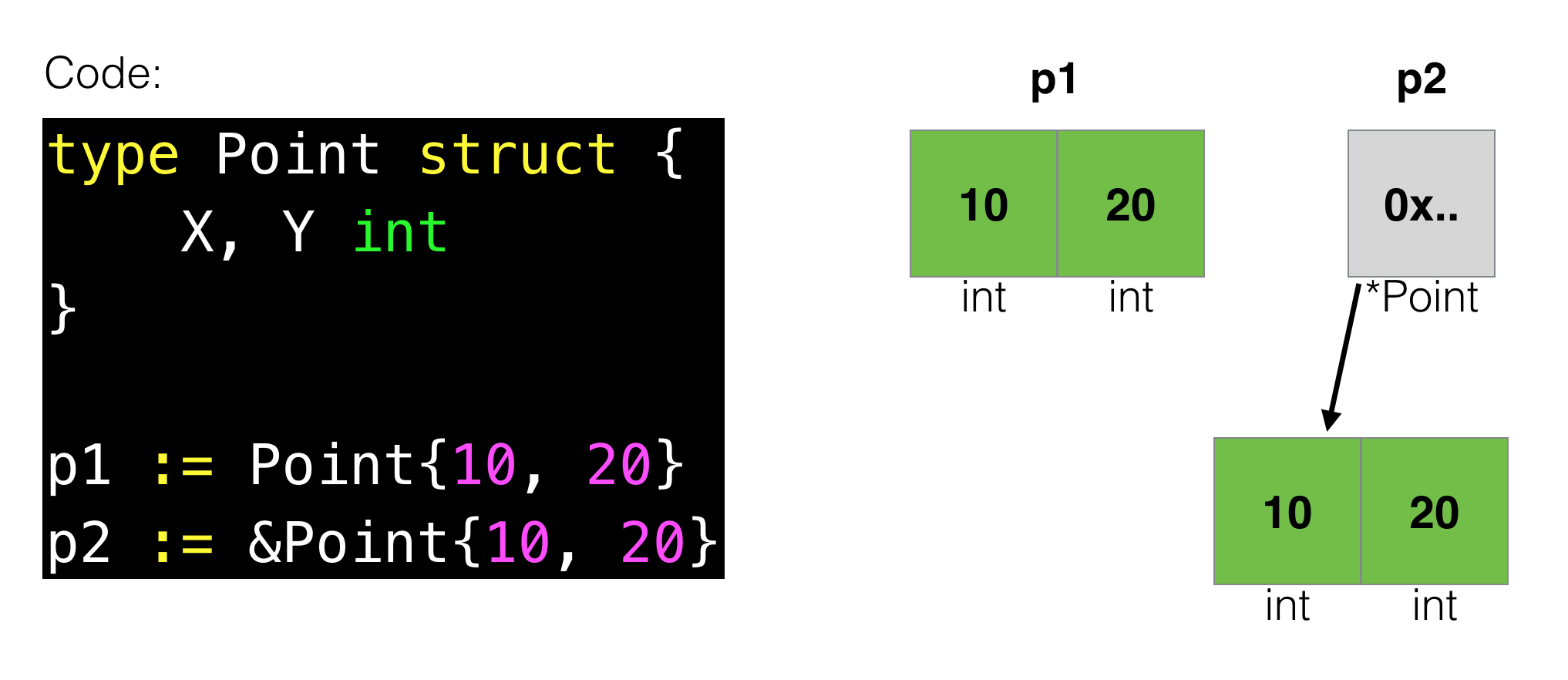 Address in memory is usually represented by hex value, hence “0x…” in the picture. But the knowing that “pointer’s value” may be in one place, while “actual data, referenced by pointer” - in another, will help us in the future.
Address in memory is usually represented by hex value, hence “0x…” in the picture. But the knowing that “pointer’s value” may be in one place, while “actual data, referenced by pointer” - in another, will help us in the future.
Now, one of the “gotchas” for the beginners in Go, especially who has no prior knowledge of languages with pointers, is a confusion between “passing by value” of function parameters. As you may know, in Go everything is passed “by value”, i.e. by copying. It should be much easier, once you try to visualize this copying:
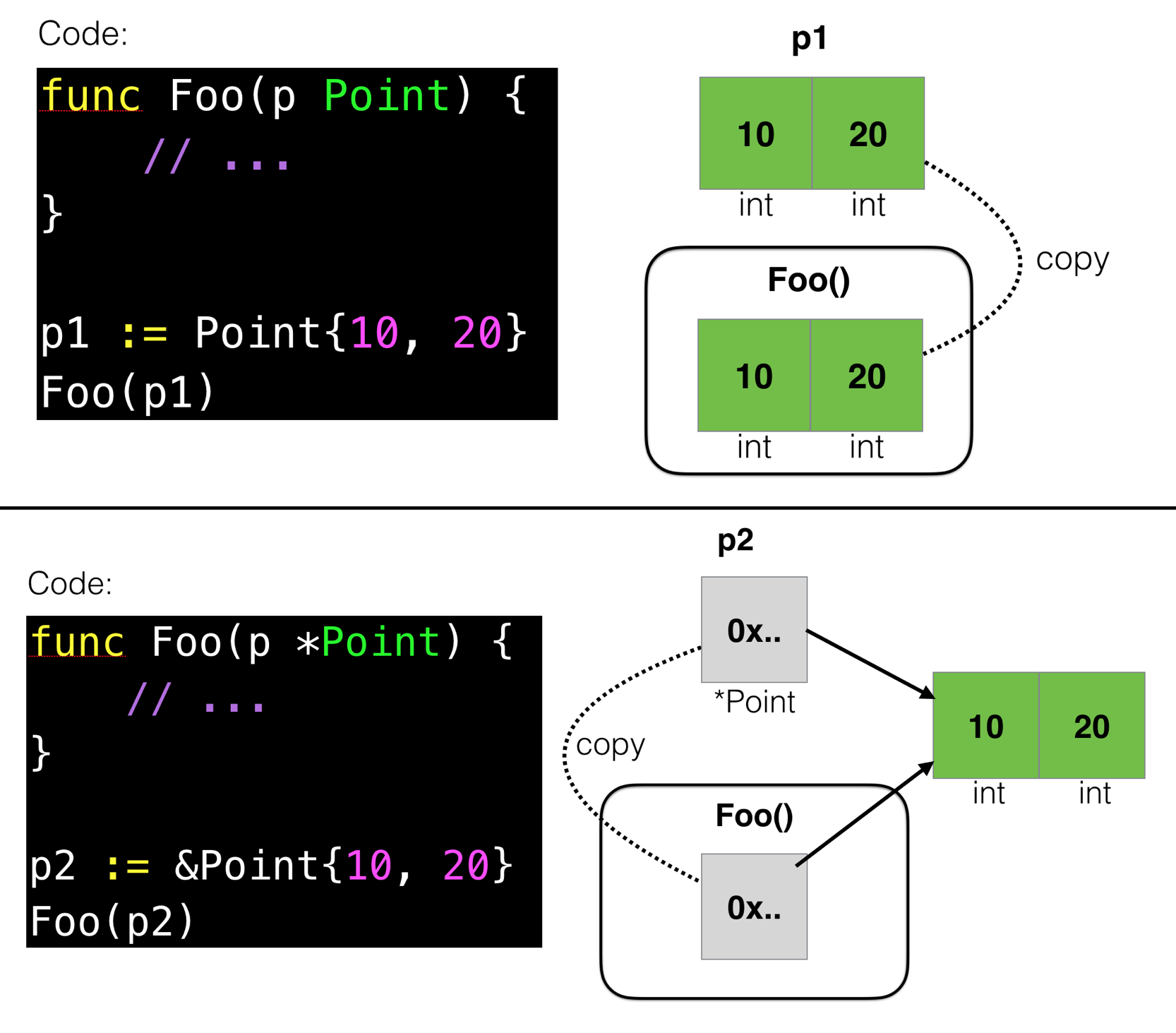 In a first case, you copy all those blocks of memory - and in reality, it’s often much more than 2 - it may easily be 2 million of blocks, and you have to copy them all, which is one of the most expensive operations. But in the second case, you copy only one block of memory - which contains the address of actual data - and is fast and cheap.
In a first case, you copy all those blocks of memory - and in reality, it’s often much more than 2 - it may easily be 2 million of blocks, and you have to copy them all, which is one of the most expensive operations. But in the second case, you copy only one block of memory - which contains the address of actual data - and is fast and cheap.
Now, you naturally can see that modifying p in the function Foo() will not modify original data in a first case, but definitely will modify in the second case as the address stored in p is referencing original data blocks.
Okay, if you got the gist of how knowing internal representations can help you avoid common gotchas, let’s dive a bit deeper.
Arrays and Slices
Slices at the beginning are often confused with arrays. So let’s take a look at arrays.
Arrays
var arr [5]int
var arr [5]int{1,2,3,4,5}
var arr [...]int{1,2,3,4,5}
Arrays are just continuous blocks of memory, and if you check the Go runtime source code (src/runtime/malloc.go), you may see that creating an array is essentially an allocating a piece of memory of the given size. Old good malloc, just smarter :)
// newarray allocates an array of n elements of type typ.
func newarray(typ *_type, n int) unsafe.Pointer {
if n < 0 || uintptr(n) > maxSliceCap(typ.size) {
panic(plainError("runtime: allocation size out of range"))
}
return mallocgc(typ.size*uintptr(n), typ, true)
}
What does it mean for us? It means that we can simply represent array as a set of blocks in memory sitting next to each other:
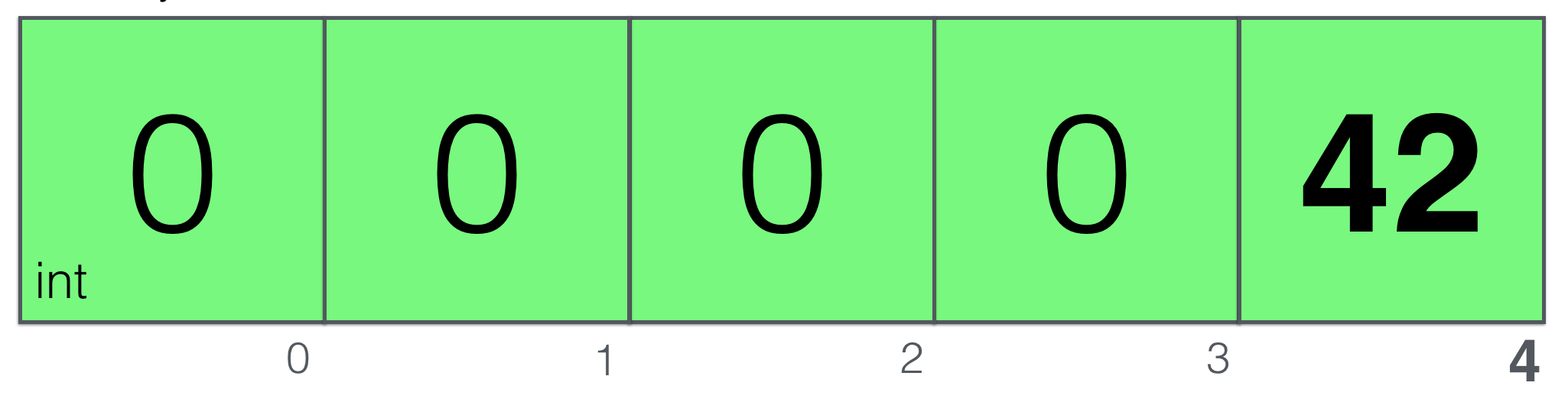
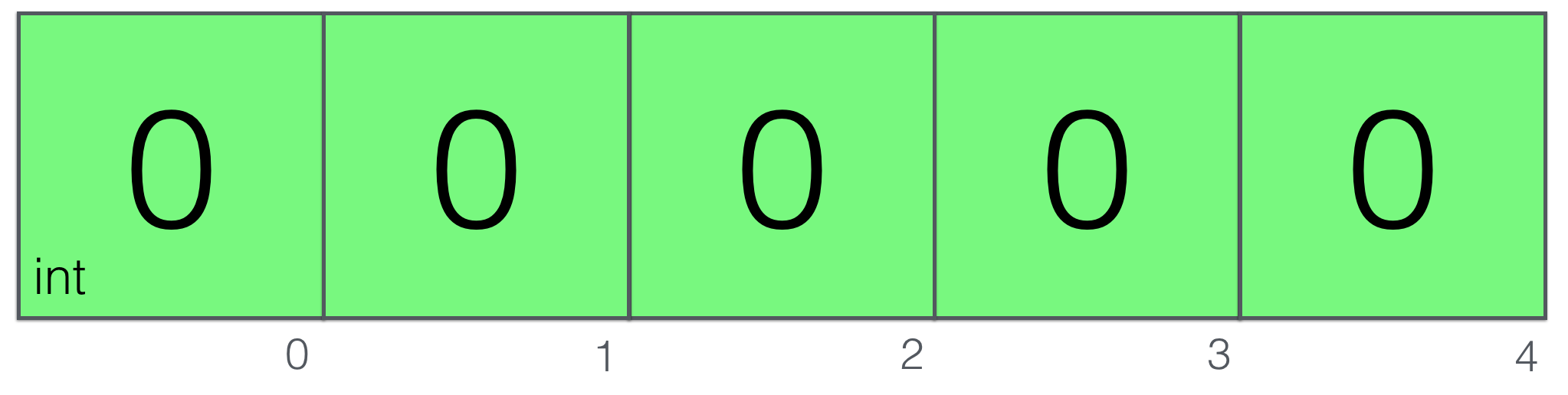 Array elements are always initialized with zero values of its type, 0 in our case of
Array elements are always initialized with zero values of its type, 0 in our case of [5]int. We can index them and get the length using len() built-in command. Nothing else, basically.
When you refer to the single element in the array by index and doing something like this:
var arr [5]int
arr[4] = 42
you’re taking the fifth (4+1) element and change its value:
 Now, we’re ready to explore the slices.
Now, we’re ready to explore the slices.
Slices
Slices at the first glance are similar to arrays, and the declaration is really similar:
var foo []int
But if we go to the Go source code (src/runtime/slice.go), we’ll see that, in fact, Go’s slices are structures with three fields - pointer to array, length and capacity:
type slice struct {
array unsafe.Pointer
len int
cap int
}
When you create a new slice, Go runtime will create this three-blocks’ object in memory with the pointer set to nil and len and cap set to 0. Let’s represent it visually:
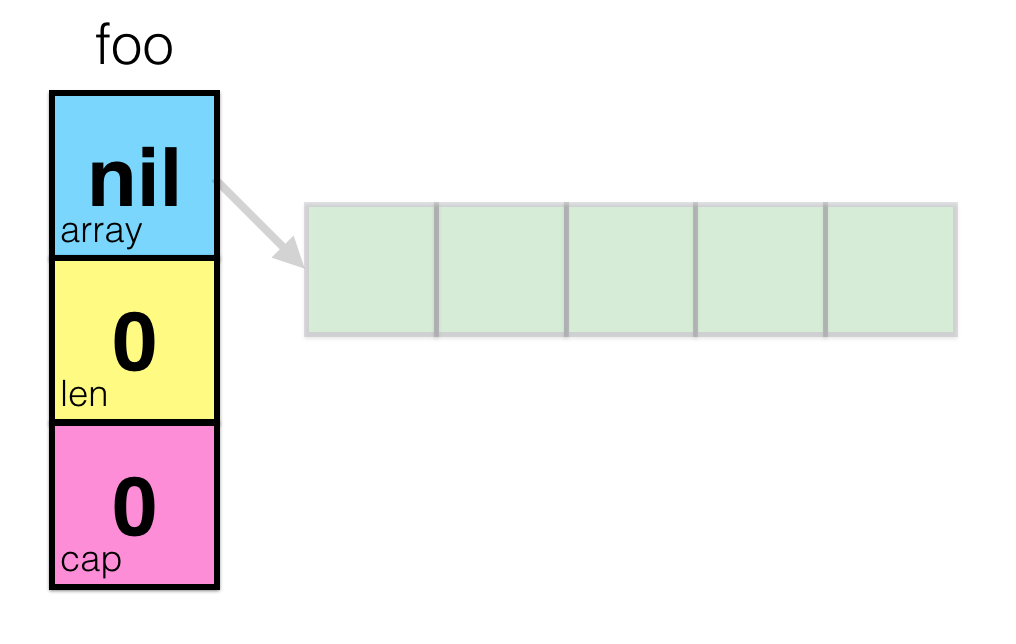 That’s not very interesting, so let’s use
That’s not very interesting, so let’s use make to initialize slice of the given size:
foo = make([]int, 5)
will create a slice with an underlying array of 5 elements, initialized with 0, and will set both len and cap to 5.
Cap means capacity and helps to reserve more space for the future growth. You can use make([]int, len, cap) syntax to specify capacity. In fact, you’re almost never will have to deal with that, but it’s important to understand the concept of capacity.
foo = make([]int, 3, 5)
Let’s take a look at both cases:
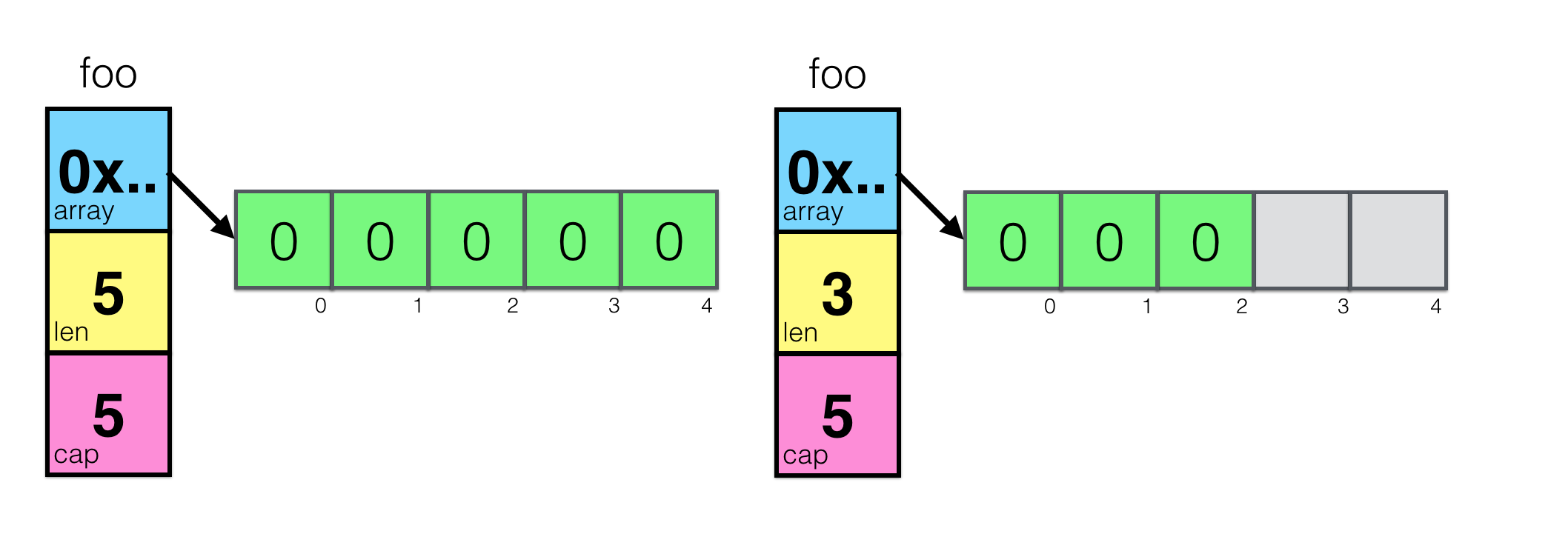
Now, when you update some elements of the slice, you’re actually change the values in the underlying array.
foo = make([]int, 5)
foo[3] = 42
foo[4] = 100
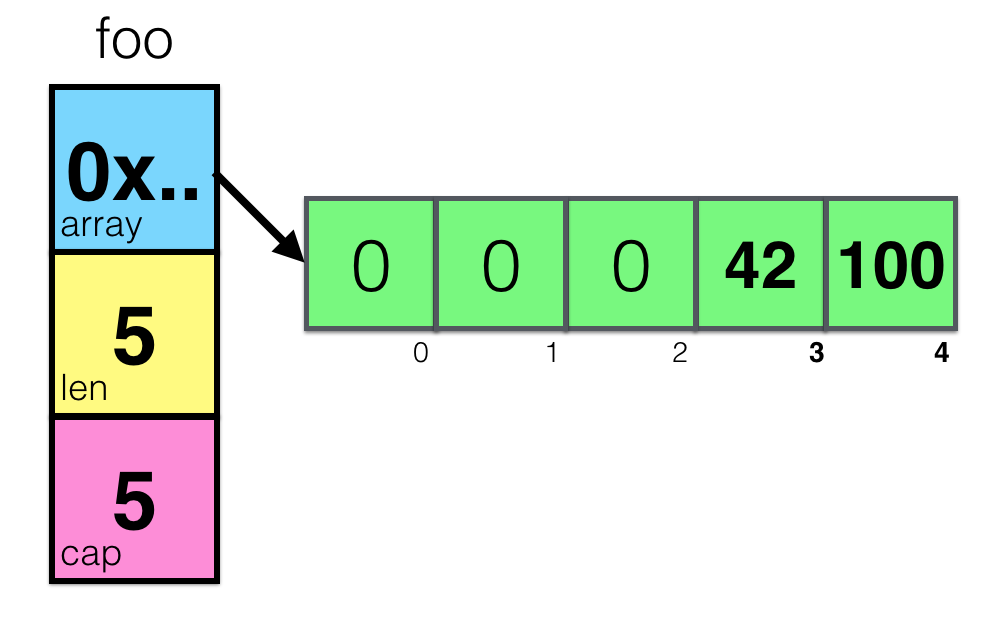
That was easy. But what will happen, if you create another subslice and change some elements? Let’s try:
foo = make([]int, 5)
foo[3] = 42
foo[4] = 100
bar := foo[1:4]
bar[1] = 99
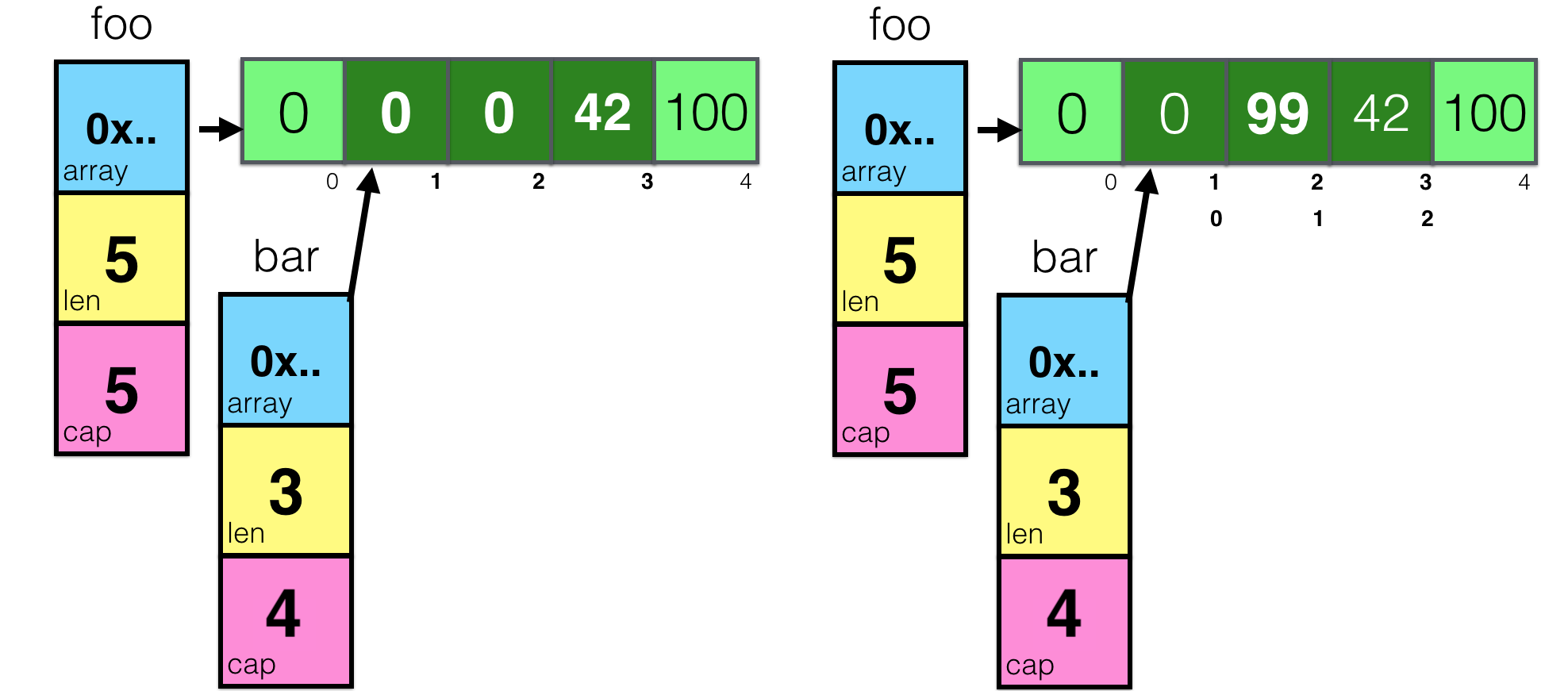
Now, you see it! By modifying bar, you actually modified the underlying array, which is also referenced by slice foo. And it’s actually a real thing, you may write something like this:
var digitRegexp = regexp.MustCompile("[0-9]+")
func FindDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
return digitRegexp.Find(b)
}
By reading let’s say 10MB of data into slice and searching for only 3 digits, you may assume that you’re returning 3 bytes, but, in fact, the underlying array will be kept in memory, no matter how large it is.
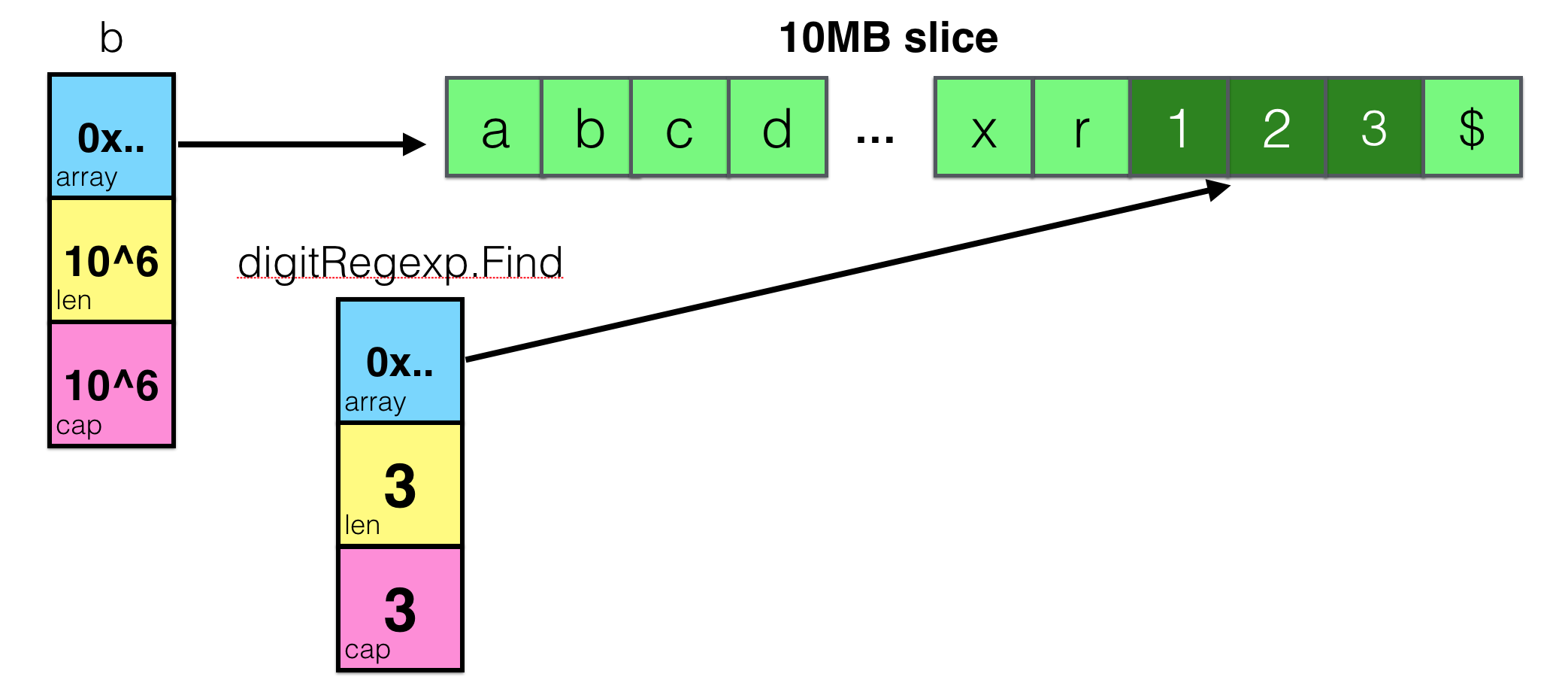
And that is one of the most common Go gotchas you may read about. But once you have this picture of internal slice representation in your head, I bet it will be almost impossible to run into it!
Append
Next to the slices’ gotchas, there are some gotchas related to the built-in generic function append(). It essentially does one operation - appends a value to the slice, but internally it does a lot of complex stuff, allocating memory in a smart and efficient way if needed.
Let’s take the following code:
a := make([]int, 32)
a = append(a, 1)
It creates a new slice of 32 ints and adds new (33rd) element.
Remember cap - capacity in the slices? Capacity stands for capacity to grow. append checks if the slice has some more capacity to grow and, if not, allocates more memory. Allocating memory is a quite expensive operation, so append tries to anticipate that operation and asks not for 1 byte, but for 32 bytes more - twice as large as the original capacity. Again, allocating more memory in one go is generally cheaper and faster than allocating less memory many times.
The confusing part here is that, for many reasons, allocating more memory usually means allocating it at the different address and moving data from old place to the new one. It means that address of the underlying array in the slice will also change. Let’s visualize this:
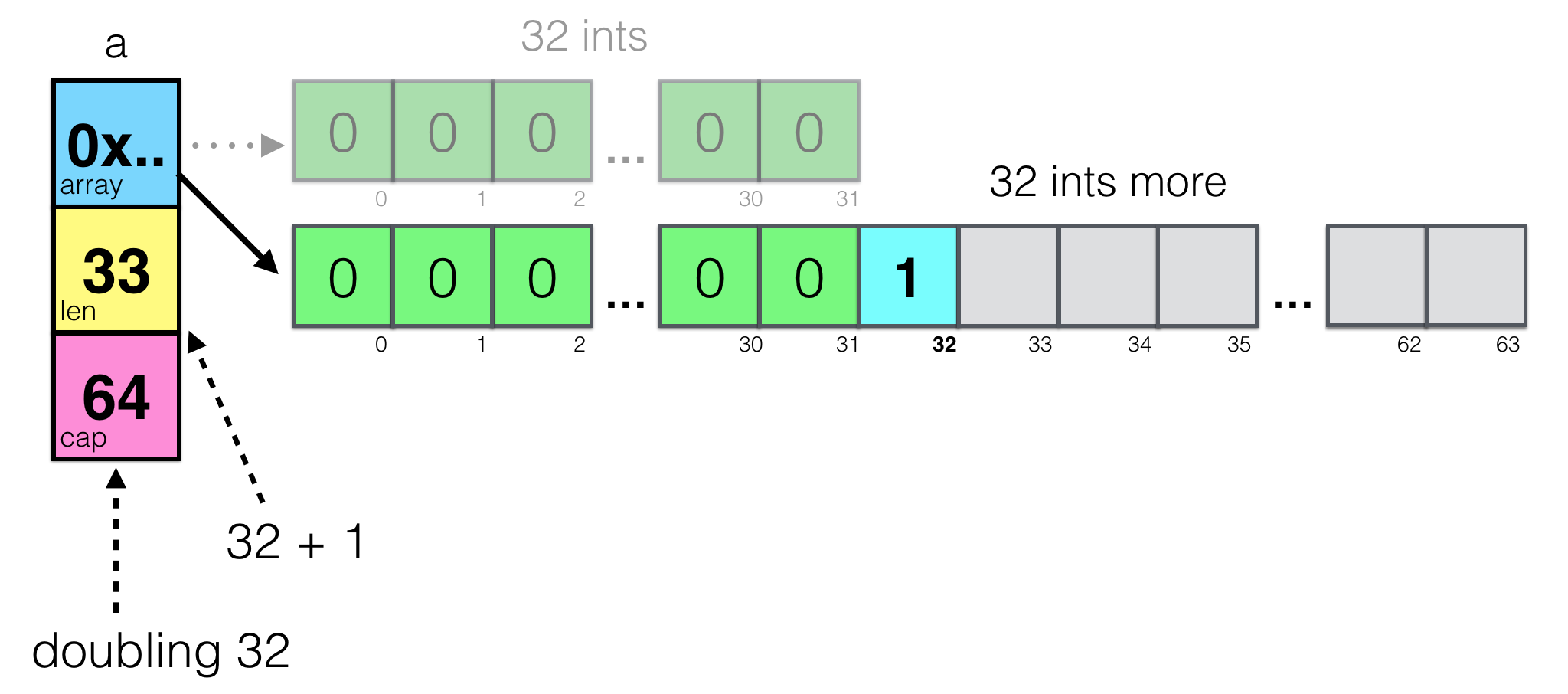 It’s easy to see two underlying arrays - old and new ones. Doesn’t look like a possible gotcha, right? The old array will be freed by GC later unless another slice is referring it. This case, actually, is one of the gotchas with append. What if you create subslice
It’s easy to see two underlying arrays - old and new ones. Doesn’t look like a possible gotcha, right? The old array will be freed by GC later unless another slice is referring it. This case, actually, is one of the gotchas with append. What if you create subslice b, then append a value to a, assuming they both share common underlying array?
a := make([]int, 32)
b := a[1:16]
a = append(a, 1)
a[2] = 42
You will get this:
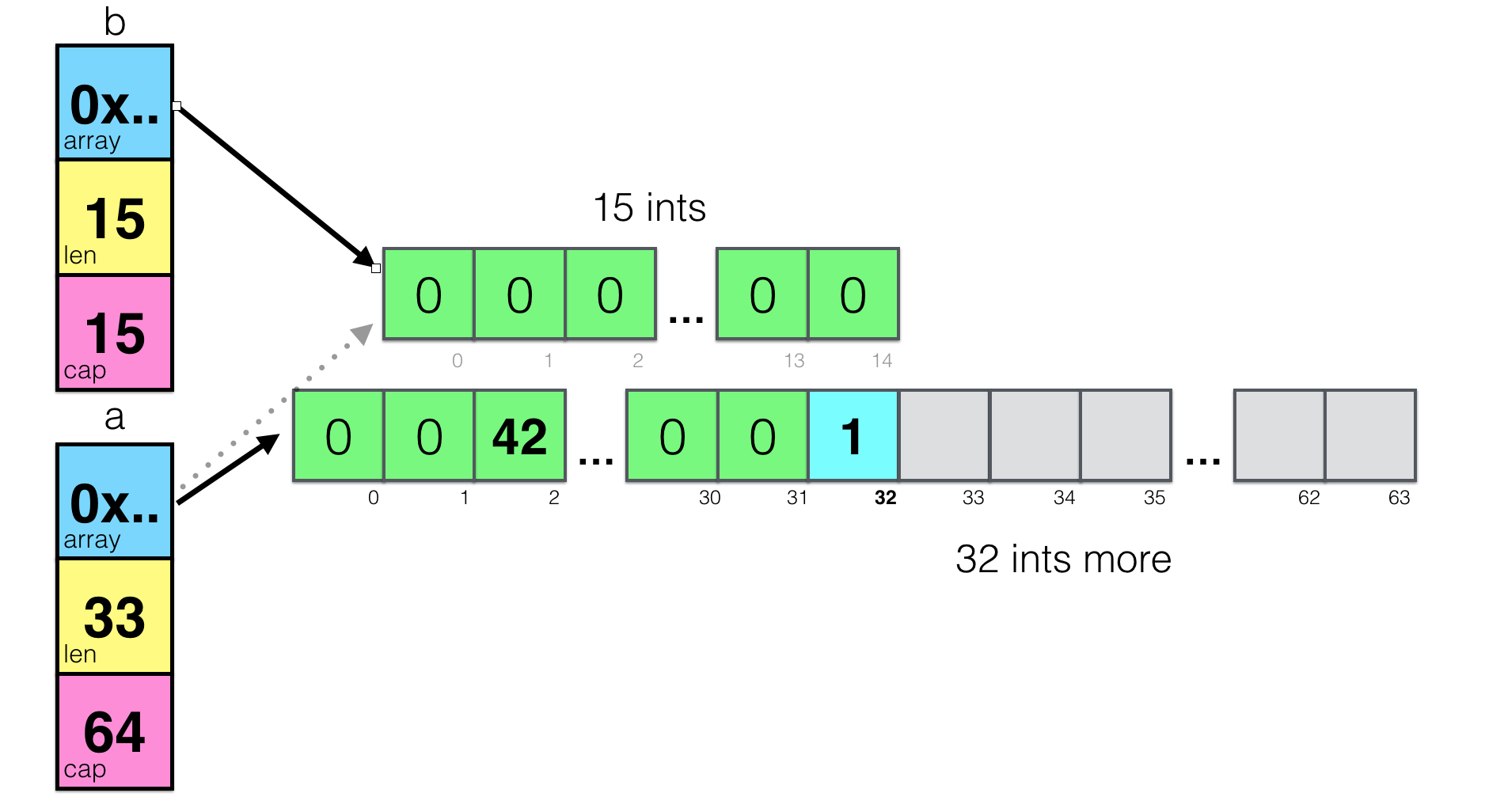 Yes, you’ll have two different underlying arrays and it may be quite contra-intuitive for the beginners. So, as a rule of thumb, be careful when you use subslices, and especially, subslices with append.
Yes, you’ll have two different underlying arrays and it may be quite contra-intuitive for the beginners. So, as a rule of thumb, be careful when you use subslices, and especially, subslices with append.
By the way, append grows slice by doubling it’s capacity only up to 1024, after that it will use so-called memory size classes to guarantee that growth will be no more than ~12.5%. Requesting 64 bytes for 32 bytes array is ok, but if your slice is 4GB, allocating another 4GB for adding 1 element is quite expensive, so it makes sense.
Interfaces
Okay, this is the most confusing thing for many people. It takes some time to wrap your head around proper usage of interfaces in Go, especially after having a traumatic experience with class-based languages. And one of the sources of confusion is a different meaning of nil keyword in the context of interfaces.
To help understand this subject, let’s again take a look at the Go source code. What is interface under the hood? Here is a code from src/runtime/runtime2.go:
type iface struct {
tab *itab
data unsafe.Pointer
}
itab stand for interface table and is also a structure that holds needed meta information about interface and underlying type:
type itab struct {
inter *interfacetype
_type *_type
link *itab
bad int32
unused int32
fun [1]uintptr // variable sized
}
We’re not going to learn the logic of how interface type assertion works, but what is important is to understand that interface is a compound of interface and static type information plus pointer to the actual variable (field data in iface). Let’s create variable err of interface type error and represent it visually:
var err error
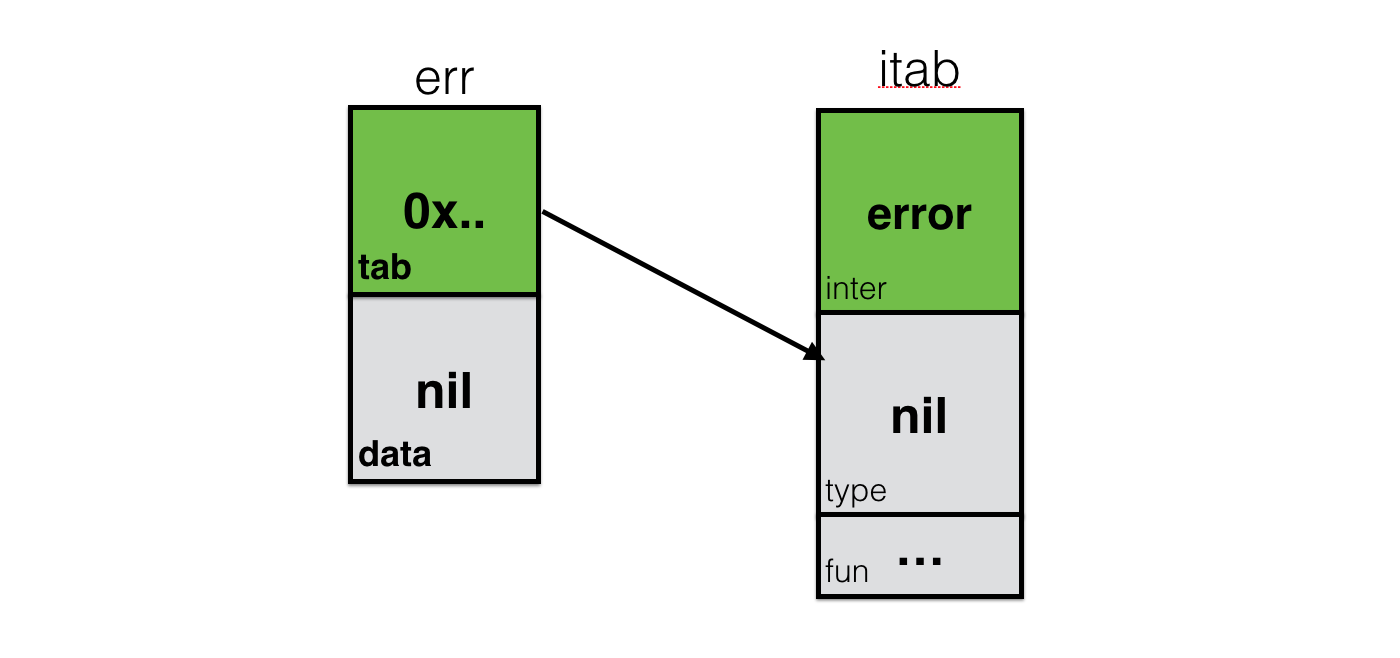
In fact, what you see in this picture is the thing called nil interface. When you return nil in the function with return type error, you are returning this object. It has information about interface (itab.inter), but has nil in data and itab.type fields. This object will evaluate to true in the if err == nil {} condition.
func foo() error {
var err error // nil
return err
}
err := foo()
if err == nil {...} // true
Now, famous gotcha is to return a *os.PathError variable which is nil.
func foo() error {
var err *os.PathError // nil
return err
}
err := foo()
if err == nil {...} // false
Those two pieces of code are similar unless you know how the interface looks like inside. Let’s represent this nil variable of type *os.PathError being wrapped in an error interface:
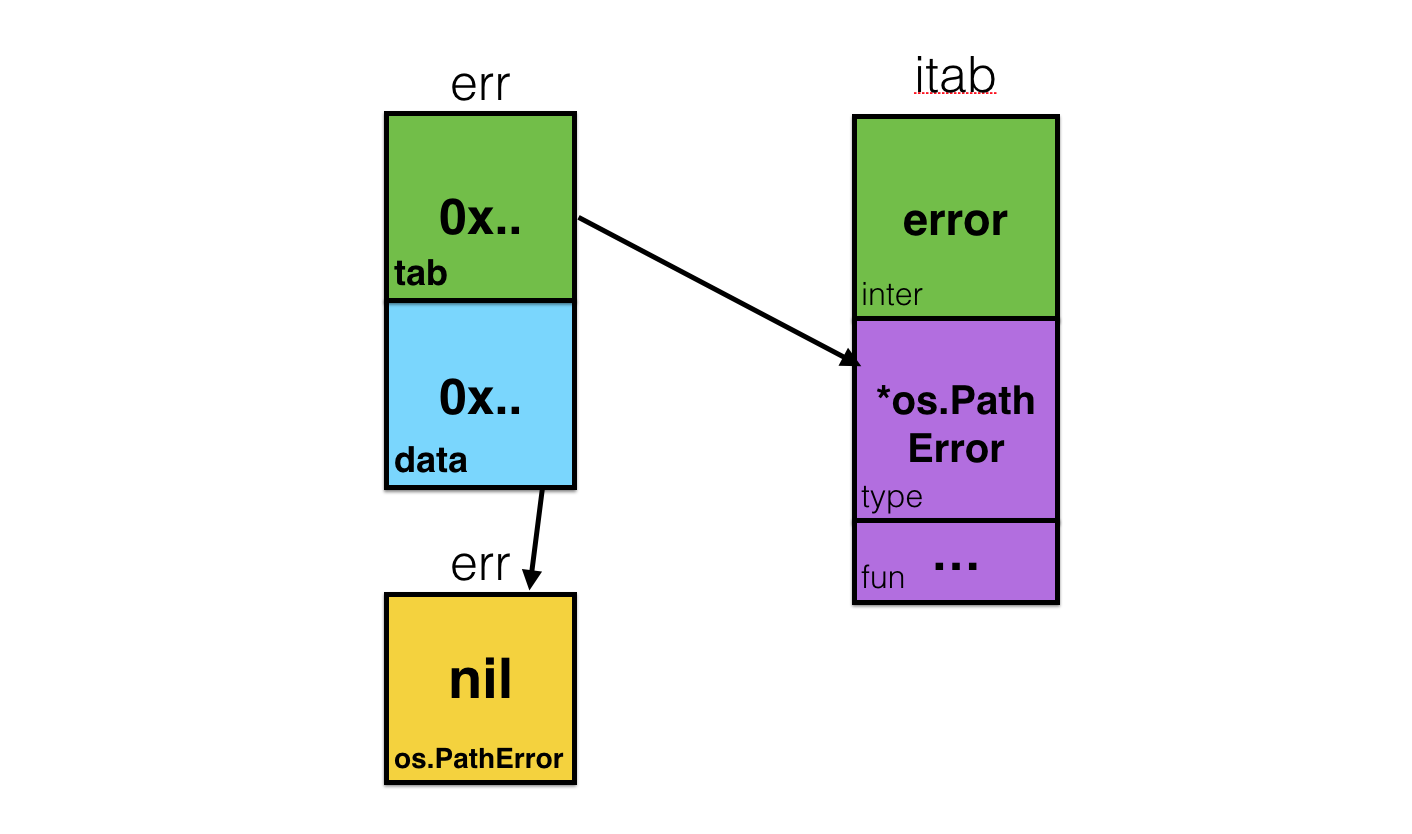 You can clearly see the
You can clearly see the *os.PathError variable - it’s just a block of memory holding nil value because it’s the zero value for pointers. But the actual error that we return from foo() is a much complex structure with information about the interface, about the underlying type and the memory address of that block of memory, holding nil pointer. Feel the difference?
In both cases, we have nil, but there is a huge difference between “have an interface with a variable which value equals to nil” and “interface without variable”. Having this knowledge of internal structure of interfaces, try to confuse these two examples now:
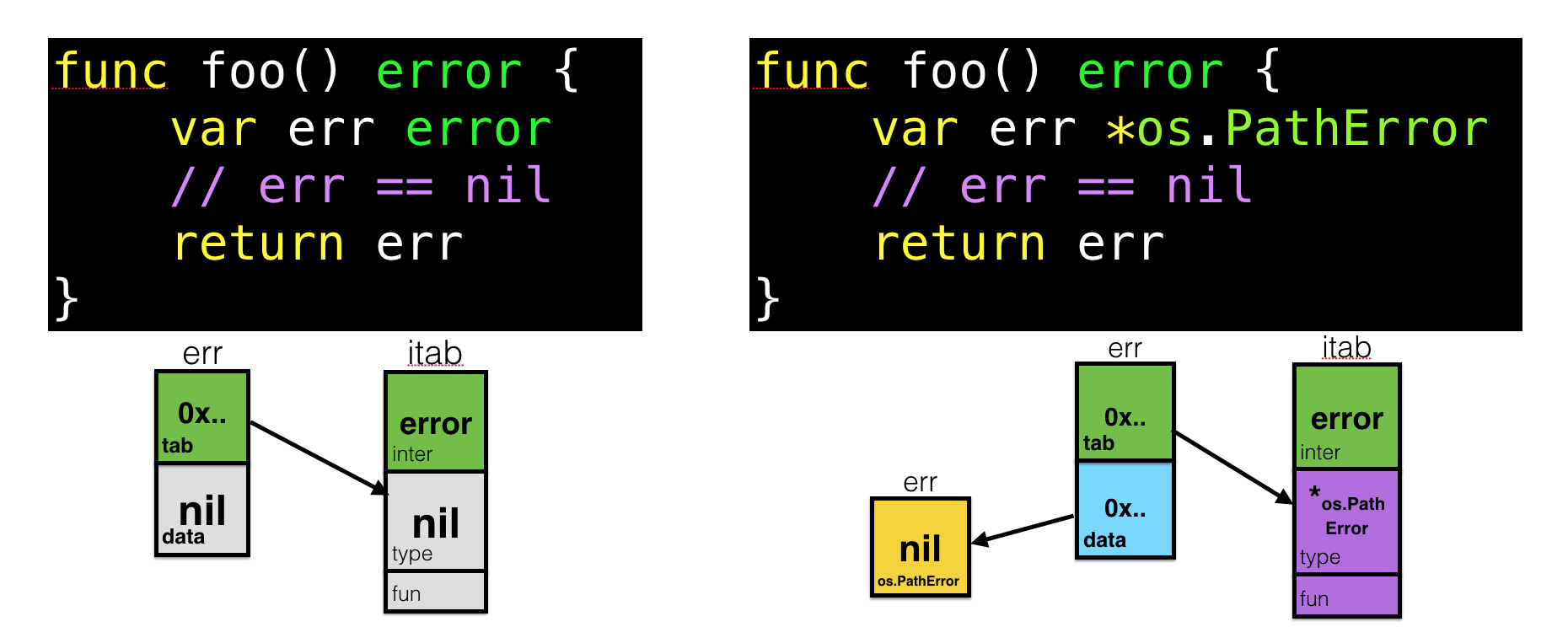 Should be much harder now to run into that gotcha.
Should be much harder now to run into that gotcha.
Empty interface
A few words about empty interface - interface{}. In the Go source code (src/runtime/malloc.go it’s implemented using own structure - eface:
type eface struct {
_type *_type
data unsafe.Pointer
}
As you may see, it’s similar to iface, but lacks interface table. It just does not need one because by definition empty interface is implemented by any static type. So when you wrap something - explicitly or implicitly (by passing as a function argument, for example) - into interface{}, you actually working with this structure:
func foo() interface{} {
foo := int64(42)
return foo
}
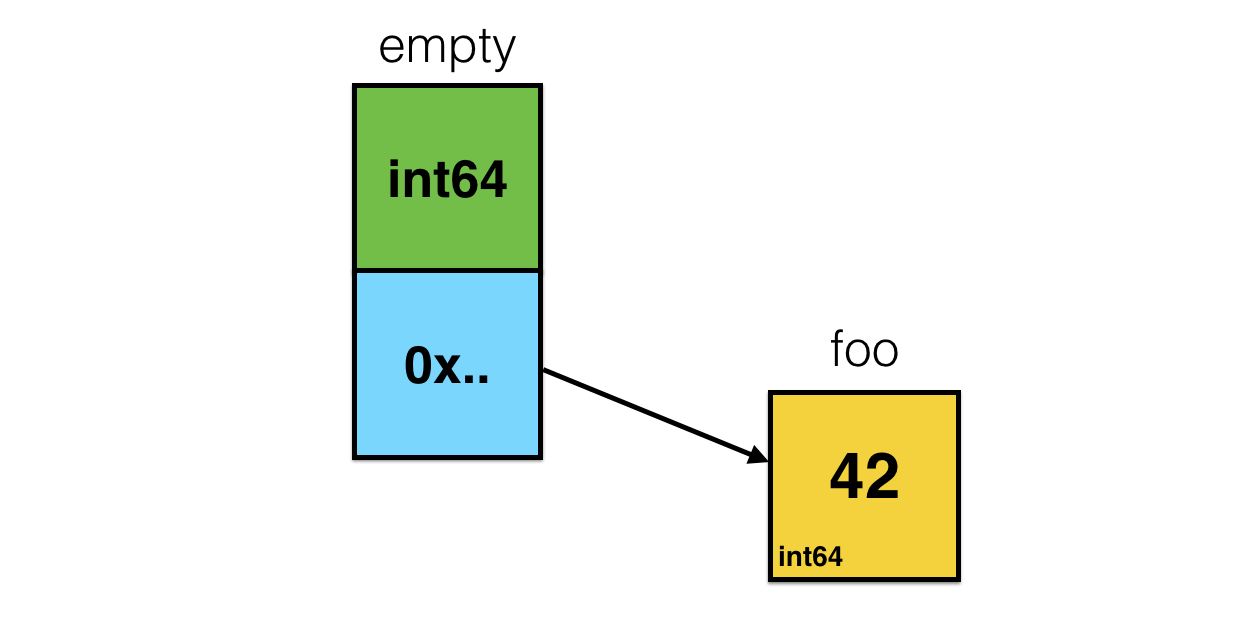
One of the interface{} related gotchas is the frustration that you can’t easily assign slice of interfaces to slice of concrete types and vice versa. Something like
func foo() []interface{} {
return []int{1,2,3}
}
You’ll get compile time error:
$ go build
cannot use []int literal (type []int) as type []interface {} in return argument
It’s confusing and the beginning. Like, why I can do this conversion with a single variable, but cannot do with slice? But once you know what is an empty interface (take a look at the picture above again), it becomes pretty clear, that this “conversion” is actually a quite expensive operation which involves allocating a bunch of memory and is around O(n) of time and space. And one of the common approaches in Go design is “if you want to do something expensive - do it explicitly”.
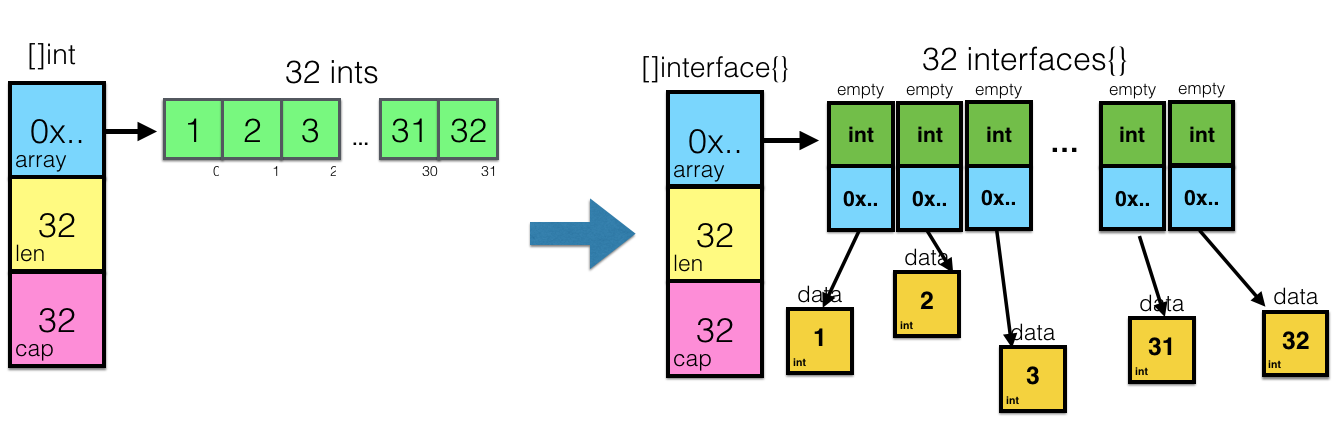 Hopefully, it makes sense to you now as well.
Hopefully, it makes sense to you now as well.
Conclusion
Not every gotcha can be attacked by learning internals. Some of them are simply the difference between your past and new experience, and we’re all have somehow different background and experience. Nevertheless, there a many of the gotchas that can be successfully avoided simply by understanding a bit deeper how Go works. I hope explanations in this post will help you build intuition on what is happening inside your programs and will make you a better developer. Go is your friend, and knowing it a bit better would not hurt anyway.
If you’re interested in reading more about Go internals, here are a list of links that helped me:
And, of course, timeless source of usefull stuff :)
Happy hacking!
PS. I also gave a similar talk on Golang BCN Meetup in November ‘16.
Here are the slides: How To Avoid Go Gotchas.pdf