Rethinking Visual Programming with Go
This is a blog version of the talk I gave at GopherCon Europe 2019 (Canary Islands Edition), where I shared my thoughts on why Visual Programming Languages have failed and revealed for the first time my experiment on visualizing Go code.

I could dive in straight into the project, but I do believe to truly appreciate it, I have to explain the thought line behind it first.
It starts with an almost existential frustration of working with code as a text.
IDE vs Fire Torch
Do you know what’s common between your code editor and the fire torch?
Historically, we read source code text in a top-down left-to-right fashion – the same way as we read western natural languages – and because of a horizontal writing system, it grows downwards, forming long vertical pieces of text, stored in files.
To read that text and navigate its structure, we use code editors – specialized text editors with integrated syntax highlighting and code analysis features. I use Vim and enjoy its comforting look and feel of the console-based interface, but many people prefer more advanced code editors, rich on mouse-focused interaction. In any case, we do scroll a text and jump between files a lot.
We so used to this daily routine, that it might be hard to zoom out and see it from a distance. But if you do that, you’ll see that in fact, you’re sitting in front of a wall of texts, and use this sliding window called “editor” to move around the wall and bring the small fraction of it onto your screen so you can see it closer.
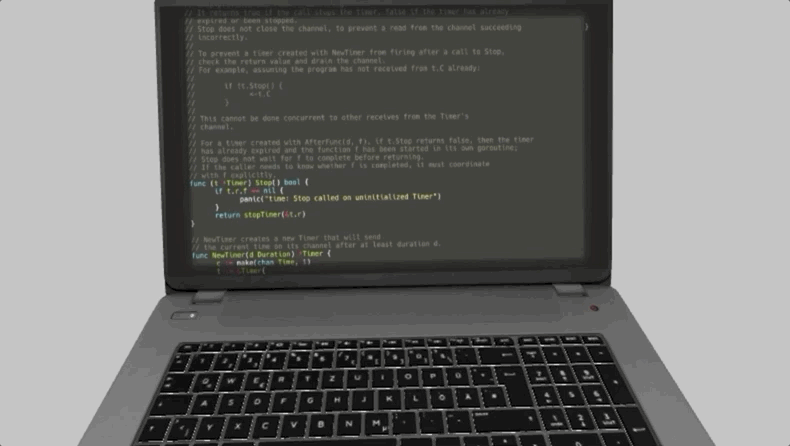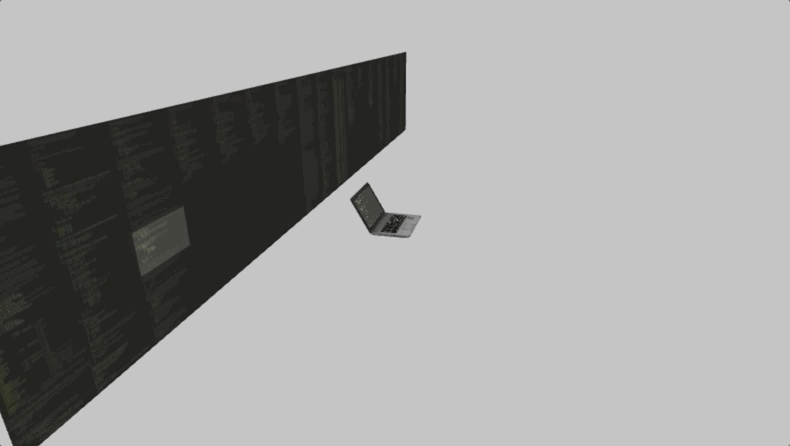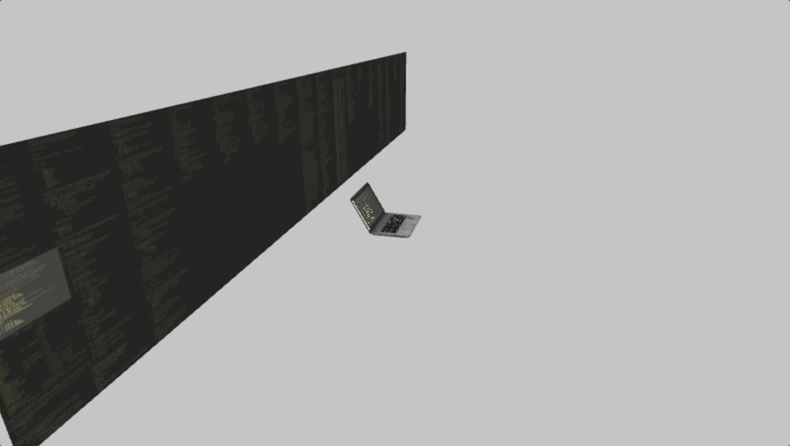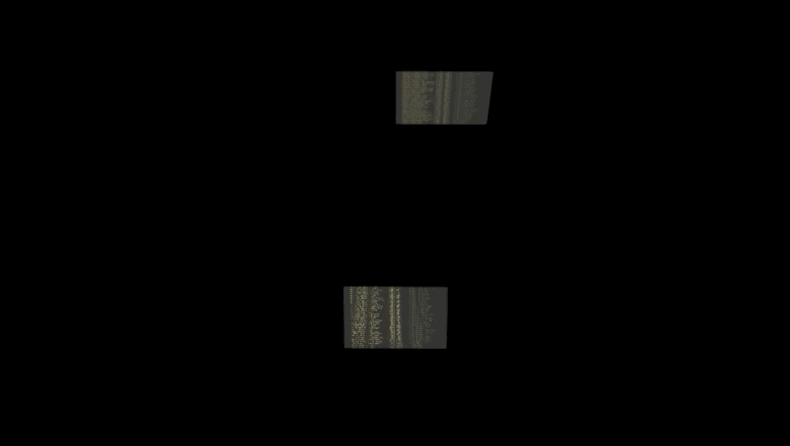
As you never see the rest of the code, except that one on your screen, it means the whole wall is in the darkness.
So here you are – sitting alone in the darkness, surrounded by the walls with mysterious texts, – and using the code editor to shine a beam of light onto this wall to read a small part of it. Now, just imagine the fire torch here instead of a glowing screen, and you’ll see that your editor is just a modern version of a fire torch.

When you read a new codebase, you’re like an ancient person in a dark cave, using a fire torch to read the wall writing or paintings.

That’s quite ancient approach, I must say. Of course, there is nothing wrong about resembling ancient interactions with the world. Except I have so many issues with it! We spend 90% of the time reading code, and only 10% writing it, and that 90% happen to be my least favourite part.
We spend 90% of the time reading code, and only 10% writing it, and that 90% happen to be my least favourite part.
Reading code requires incredibly good attention, near-perfect concentration, more than average memorization skills and it is stupidly tedious. And my gut feeling tells me that textual form contributes to it significantly. When I’m about to read new codebase or big pull-request, my face resembles that hermit’s face in the cave.
Even more, studies on code comprehension using eye-tracking systems confirm that we read the source code and standard text quite differently. We don’t read it continuously line-by-line but show clear scanning patterns like fixating gaze on cognitively challenging parts of code or areas of interest, jumping back and forth and skipping some lines or whole blocks altogether.
![]()
What if the text is not the best form of representing code?
Visual programming
Obviously, I’m not the first person reflecting on the shortcomings of the textual representation of the code. There is a whole field of Visual Programming Languages or VPLs, and there were literally hundreds of languages developed over the last 60 years.
On the Internet you may find some well-prepared materials and literature with overview and history of VPLs – I’ll just link two I liked most: huge curated page with a bunch of links and snapshots of different VPLs and nice talk “Visual History of Visual Programming Languages” by Emily Nakashima.
Here is a very brief overview and an attempt to classify them into two and a half groups:
1. Block-based VPLs
Block-based visual languages are environments where you don’t input code as a text, but rather drag-and-drop predefined blocks into the script area. Many of them require no typing skills at all, have nice colourful UIs and virtually make syntax errors impossible.
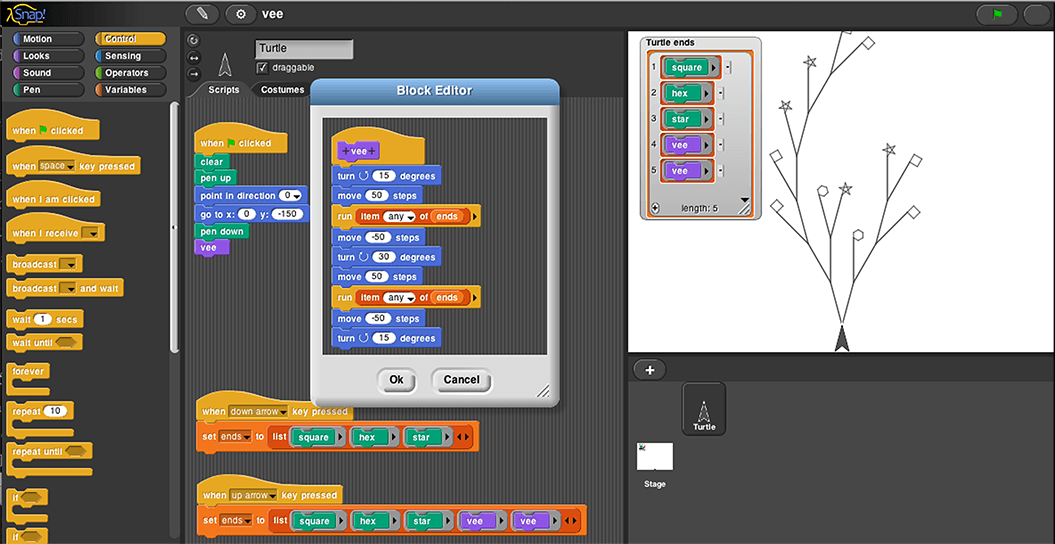
You may have heard about such languages as Scratch, MIT App Inventor, Google Blockly, and so on. They focus mostly on teaching programming basics to children, novice programmers and heavily used in schools and events like Hour of Code throughout the world. Multiple studies confirm their positive impact on the students’ retention in Computer Science classes. Plus, many hybrid projects allow you to convert simple code samples from the textual representation of mainstream languages into the block representation and vice-versa, which seems to help in the transition from block-based classes to “real programming”.
But that seems to be mostly their limit. Plus, a lot of people say it’s not visual programming at all – just replacing keyboard input with mouse input. And I tend to agree here.
2. Flow-based VPLs
Another large group of visual programming languages is actually a subgroup of so-called flow-based languages, also known as node-based programming languages. They use flow charts to represent changes of state-, logic- or data.
Sometimes reasoning behind those languages is that the logic of the program should be implemented by people who know problem domain well - like doctors or engineers - and actual translation of that logic into the code is a job for other people or programs. Which kinda makes sense.
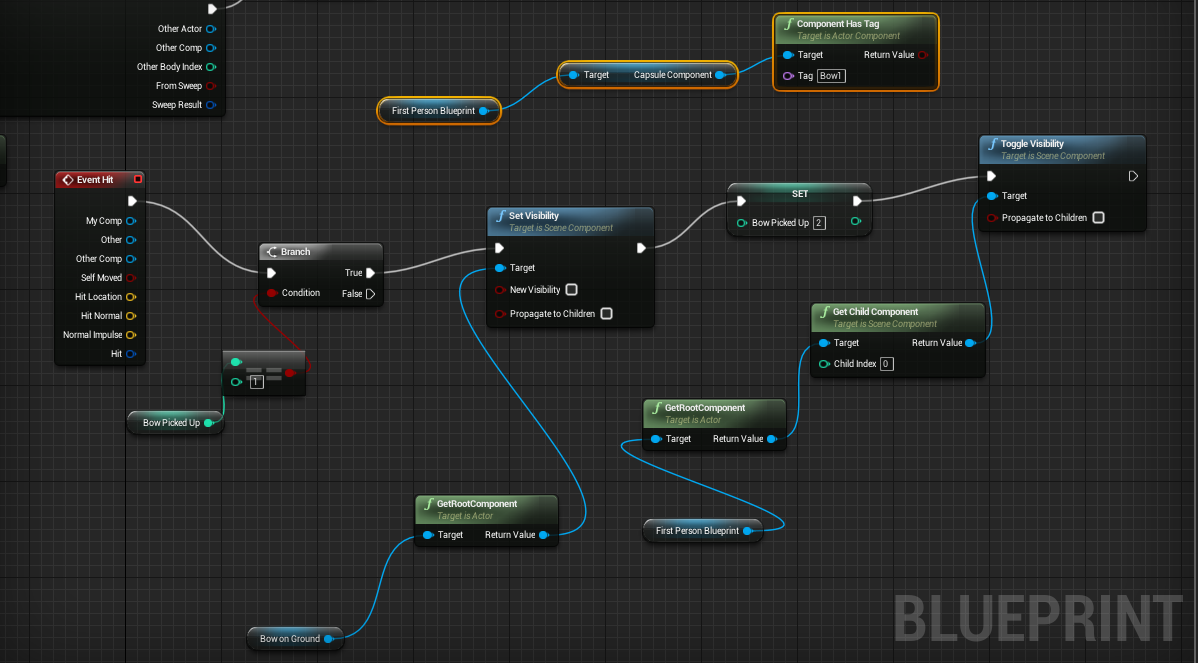
There are many attempts to make sort of universal flow-based VPLs, like Raptor, Flowgorithm, Visual Logic or DRAKON, but the biggest popularity this approach gained in niche fields like 3D programming, music synthesis, signal processing or IoT/embedded circuits design tools. You might be familiar – or even using yourself on a daily basis – such tools like Unreal Blueprints, Max/MSP, National Instruments’ Labview or Autodesk Dynamo. Those tools are actively and heavily used in practice by many people, but they’re still quite narrow-field and highly specialized solutions. It’s unlikely you will be writing raytracing engine or kernel driver or GraphQL server using one of those.
2.5 Exotic VPLs
There are also a bunch of more exotic and harder to classify things like Prograph or Cables. Prograph, for example, designed in the 80s, was first truly visual object-oriented language and introduced some interesting ideas that I liked, but my attempt to use its modern reincarnation failed miserably.
Also, Pygmalion from the 70s is particularly interesting, as it was a great example of a somehow forgotten programming technique called Programming by Demonstration. It basically means that you program algorithm not by coding, but by demonstrating it to the machine – really cool and somehow underexplored area.
No mainstream VPL?
But there is no truly mainstream general purpose Visual Programming Language at the moment. By every single metric, modern programming languages landscape is 100% dominated by textual programming languages with zero exceptions.
Why is it so? An old adage tells us “A picture is worth a thousand words” and intuitively we know that text is clearly not the best way to represent everything. All those bright minds working on the visual programming languages were clearly onto something, but seems like we are missing something essential to make visual programming a reality.
Why VPLs failed?
That question piqued my curiosity long time ago and, in short, my answer is simply that we have no idea what we are doing. There is no commonly accepted scientific explanation of what programming is. We just brute-force different approaches designing new languages – visual and textual – and hope they’ll work with our minds better.
Even worse, I have an increasingly growing feeling that PLT (Programming Language Theory) community actually doesn’t even care about it. At least I’ve never seen properly conducted studies involving psychologists or neuroscientists upon introducing yet another new fancy feature into a programming language. I’d love to be brutally wrong here, though.
So, we agree that we need code to represent abstractions, but what exactly does it mean? What happens in your mind when you read, write or even think about the code? Through the lens of which framework do you even validate and measure if visual language performs better or worse?
I rarely see those questions asked, let alone satisfying answers to them.
And if you attempt to answer those questions yourself, you inevitably end up either in the realm of philosophy or neuroscience, or both. As I always have been interested in how our brain works, reading books and papers on brain-related subjects became kinda a hobby of mine and, I think, helped me to start seeing those questions in the new perspective. And while neuroscientists are barely scratching the surface of how our brain works, and I’m just scratching the surface of what they’re scratching, I want to share two important and not entirely obvious aspects that, I believe, are fundamental to the topic. At least, they’ll be important to follow my though line further in the text, as I’m going to build up my reasoning on it.
Human Brain 101
The human brain consists of roughly 90-100 billion neurons that forms more than 1000 trillion connections, which makes it the most complex object in the solar system, so no way it can be explained easily.
Our consciousness and thinking are believed to be in the part of the brain called neocortex. Most people know it as this wrinkled walnut-shaped thing, but you might be surprised to discover that it’s actually a flat tissue of the decent pizza size, 5-6mm thick. It’s just folded this way to fit the skull after the rapid increase of the surface area (growing skull was more evolutionary expensive, as it also implied growing pelvic bones to accommodate birth process).
This tissue is remarkably uniform in structure – it has the same 5 layers of neurons throughout the whole surface, and they’re organized in cortical columns. Some theories suggest that this cortical column is the single “computational unit” of the neocortex and performs one primary task – take an insane amount of inputs, extract patterns from them and learn how to predict them.

Consciousness, thoughts, high-level thinking, self-awareness – are “simply” a byproduct of immense scale and complexity of these patterns’ extracting tissue. We’re talking about the scale of a number of galaxies in the observable universe if it helps, the same ballpark.
Spatial vs temporal patterns
First thing I want to focus your attention here is the concept of patterns itself. There are two primary types of patterns in the universe – spatial and temporal. Spatial simply means related to space and temporal – to time. Space and time. Here and now. This difference stems from the very nature of our universe, and evolutionary brain learned to handle them accordingly.
Vision, for example, mostly deals with spatial information and visual cortex does a fantastic job on extracting tons of most common patterns from the sensory inputs provided by the retina. To capture spatial relationships, you have to get all input “at once” – you can’t see the image looking it one pixel at a time, one by one. You have to see all pixels at the same time arranged in a space in the right way.
Hearing, on the other hand, works predominantly with temporal patterns – you can’t listen to a melody by listening all notes together at the same time. They have to be spread in time.
All our sensory inputs work both with spatial and temporal patterns, of course, but vision and hearing are good examples to show the core idea of their fundamental difference. The brain handles them very differently on the lowest level, but what’s interesting is that we can use spatial representation to represent temporal information and vice versa, and, actually, often do precisely that. Musical notation is a good example – we encode temporal component with a spatial representation. The caveat here is that in order to understand it you have to train your brain to decode it back into temporal one, which is a cognitively hard task – not everybody can read musical notation and play a song in their head.
I’d love you to keep this spatial vs temporal difference in mind. It’ll be in use in a minute.
Knowledge graph
The second most important to programming aspect to know is that all your knowledge somehow stored in your neocortex as well. There is a countless number of theories that aim to explain how exactly it is stored, and I think we still far from answering those questions. But we do know that for every concept, every piece of knowledge, every abstraction or object you aware of – there is a population of neurones that get excited when you see, hear, think or even dream about it.
For example, this fantastic work by Gallant Lab in UC Berkley recorded participants’ brain activity using fMRI while they were listening labelled autostream with speech stream and mapped brain activity to labels and created interactive WebGL atlas of the brain, which you can try yourself online. You may discover that semantically close things tend to be clustered in the same part of the surface of the neocortex.
But we already know, neocortex is uniform and there is no speciality in cells. What defines the functional role of the neurone is how and whom it connected to. Each neurone – which is just a specialized cell that can handle electricity – has branched projections, called neurites – long and short, called axons and dendrites accordingly. A typical cortical neurone has, on average up to 7000 neurites, and they form connections to other neurones. Multiply 5 layers of billions of the neurones with 7K connections each on average. Good luck visualizing that in your head :)
Those connections are continually growing, rewiring and updating all your life tirelessly, forming new connections whenever you learned something and strengthen the association between two things. Collectively those connections are known as a connectome, and there is the whole field of neuroscience devoted to it called connectonomics. It’s an immensely difficult task to scan the real human brain and map all those connections and create a computer model of them, but that’s exactly what connectonomy field is trying to do. Some studies use data from the Human Connectome Project and can predict your fluid intelligence - or IQ - just by analyzing some networks of that graph, which is what connectome, in fact, is.

Think about it for a moment.
There is a physical knowledge graph in your head that represents your beliefs about reality. By physical, I mean precisely that – those are actual physical connections in the real world, like on molecular level. That’s why it’s so much easier to learn things right from scratch, instead of relearning them. You can’t just remove already grown connections. You have to grow a new one, stronger than previous.
Just to note, I don’t want to make this look simple. It’s anything, but simple. I hope neuroscientists that happen to read this post aren’t mad at me for intentionally oversimplifying things. And yet, I believe this captures the essence of what our brain does, and I’m going to build up on top of this framework.
What is Programming?
When I just started learning how to code – at the age of 6 or 7 – the essence of programming looked simple: it’s me giving orders to the computer. But it’s obviously not true anymore. Most of the modern software doesn’t even talk to the hardware directly.
When people start learning a new programming language, they often ask “Can you suggest something to practice on?” which means “I need a problem to work on in a programming language”. You don’t write code if you don’t have a problem to solve.
By “problem” I don’t mean “something bad happened” or “DDoS opportunity” – rather anything that comes from the real world – the problem domain.
The essence of writing code then is to internalize the problem domain, understand its nature, build its mental model and capture insight in a programming language.
The essence of writing code is to internalize the problem domain, understand its nature, and capture insight in a programming language.
Code as a map
In some way, code is a second-degree map of reality, with your mental map of the problem domain being the first, and code – as a map of that mental map – a second.
I like using the word “map” here because it captures the important property of maps – being a reduction of the actual thing it represents. The map is not a territory, and every map is imperfect by design. An infinitely perfect map is not a map anymore – it’s a Matrix.
The challenge with the code as a map, though, is that it should be reversible. You should be able to restore exactly the same mental model of the solution, just by reading the code. And I actually mean it – by reading the code you wrote a month ago, the same groups of neurones should be getting excited in your head, that was firing when you were writing it!
Social aspect
To make things exponentially worse, this process should be reversible also for other brains. And that’s a way more challenging task than you might think because now you can’t rely only on your mental models – but also account for other brains’ mental models. You have to build a mental model of mental models of other programmers and validate your map through it and decide if something is obvious or should be extensively commented. That’s where the social aspect of programming comes to play.
Programming is a social activity.
(Robert C. Martin)
Programming then is a purely mapping process, with the programming language being a primary mapping tool. Good code is almost always structured in such a way that it resembles the structure of the problem domain (and you can see here a glimpse of the Conway law around the corner, can’t you?).
You know those moments when a new, absolutely unanticipated requirement to your program comes in, and you realize that it simply fits well into the code design and requires a minor change? A bit exaggerating, but I live for those moments.
Good code is always a good map of your mental map of the problem domain.
Mappers vs Packers
But not all people are good mappers.
In the essay “Programmers’ Stone” written 20 years ago authors set out to explain why some developers are the order of magnitude more useful than others, and introduced the idea of “mapping” and “packing” mindsets. It’s not a scientific concept or anything, but I think authors were onto something, and reading that influenced me a lot back then.
Mappers have an internal mental map of the world which is kind of an object model that has a rich variety of connections and associations. They constantly populate and develop their mental maps of the world, and each new information is attempted to be placed on the correct place in this internal map.
It gives knowledge a structure, enables real understanding and ability to see causes and effects.
Packers, on the other hand, pack knowledge in their head, without properly building connections. It’s just a matter of remembering and learning the right responses. Understanding the world for them is a question of maximizing a number of knowledge package remembered.
I don’t often mention about this essay because it’s kinda drawing a line between people – with packers being on the wrong side, and authors claiming that world populated by packers. Being a mapper doesn’t make you a good person, and being a packer doesn’t make you a bad one. But, most of all, we’re all both mappers and packers, with some bias towards former or latter. But still, that concept resonates with all my practical experience and observation on how people think, so I think it’s worth mentioning here.
How do I decode code maps
Speaking about an observation on thinking - self-reflection might be a tough call for many, but I always enjoyed observing what happens in my head, so analyzing what happens when I program or read the code was not an entirely alien task for me.
At some point, I realized that absolutely every problem I ever worked with is spatiotemporal by nature. It has both spatial and temporal components. Spatial part captures relationships between things. Temporal – how they interact over time with each other.
Step 1: Spatial relationships
It seems that when I open unfamiliar codebase, the first step I’m going through is building a temporary internal map of what this code even represents, and try to link lines of code or file names onto my existing mental map of the problem domain this code is supposed to be related to. What’s important to note here, that this is purely spatial relationship map – I’m trying to capture objects, abstractions and their relationships and validate that map through my existing knowledge.
Imagine, I’m reading a HTTP library code. I have some (imperfect) mental map of HTTP as a protocol, and expect to see things like Client/Server, Request/Response and so on in code. When I first read the code, I’m trying to link pieces of codes to that knowledge, and build temporal map of its representation in code and validate it through my existing mental map.
That’s where the naming – the hardest problem in computer science – becomes important. In order to make those links efficiently, we need to use some shared vocabulary, and well-known symbolic representation – and that’s mostly text for now. In the future, it can be something other, like super rich emoji language – whatever is more conventional and cheaper to use. For now, it’s obviously just words.
Step 2. Temporal component
When I have those links and relationships established in my head, I expand to the temporal dimension and read the function’s code to actually see the encoded behaviour of those objects over time. If it’s not obvious, function body text differs from the rest of the source code – line order now matters and encodes temporal information. The first line is going to be executed before the second one, and we encode temporal behavioural patterns in the function code. That’s why people argue about goto operator for example – it breaks the time flow, and in Go, we have this cool keyword defer which kinda cheats on this general time flow rule – for the greater good. But the general rule about function bodies holds true - it encodes the temporal aspect of the mental map.
Visual or textual?
And that is exactly where both visual and textual representations of code are often missing the point. They attempt to express both, spatial and temporal, components in a similar fashion, and it just adds a cognitive load and doesn’t help at all.
I believe that to be the main reason why VPLs are still not the thing everybody is using and excited about. Encoding spatial component visually makes absolutely perfect sense – it’s the most natural way to encode it, but the temporal component is still better expressed with text - not perfect, but a still unbeatable human invention.
Even more, VPLs are not harnessing that power of visual representation and often focus on the purely symbolic aspect, assuming that icon vs text makes a big difference. But anyone working with data visualization knows how easy it to mess up visualization by inadvertently drawing semantically unrelated things close to each other or using colours that don’t mean anything.
Most of the VPLs I’ve seen are terrible from the visual perspective, and I don’t blame them - it’s an extremely difficult task. This Venn diagram, for example, doesn’t make sense at all, but it’s “visual” and looks cool, which is both deceptive and appealing.

Go
And that’s, finally, a point when I start talking about Go.
Go is the language that gets this mapping thing right.

It embraces the imperfect nature of maps and tries to make this mapping process as simple as possible. It doesn’t allow you to map the same thing in two different ways, which makes encoding a straightforward task - you know exactly how are you going to express the concept from your code in a Go code. Not surprisingly, it makes the reverse process – decoding – also much more comfortable. In Go, you usually don’t do the guesswork of what this piece of code actually means, and what author tried to capture here.
Perfect Language
I can’t help here but mention Gottfried Liebniz – German mathematician and philosopher whose mathematical notation we all use today.

Among other things, he was obsessed with the pursuit of perfect language, which means:
- I can say exactly what I mean.
- You can interpret the exact meaning.
- I can be sure you have interpreted it correctly and fully.
He didn’t succeed and somehow ended up inventing binary system, and I don’t think 3-rd rule is realistically achievable, but for me, Go is a language that tries hard to optimize for rules 1 and 2.
And I think any programming language designer should be obsessed with this pursuit as well. If you’re reading this and you happen to be a programming language designer of any future languages – please, design your language with these rules in mind. Design tool for mapping, not for artistic self-expression.
Spatial vs temporal mapping
Go somehow even captured the difference between spatial and temporal patterns – in Go we use concrete types to represent spatial aspect, and functions/methods – a temporal one. Plus, we have interfaces that allow generalizing on behaviour, but we’ll get there in a minute. Compare this with class-based languages where class represents all and nothing at the same time – it can be data, behaviour, both or nothing, but most of the time it’s just accidental complexity. Go makes this distinction clear, and it makes code so much easier to understand!
I remember seeing a comment on twitter where someone said: “It feels like in Go there are just types and funcs”. Not sure if it was a rant, but yeah – and in the universe, there are “just” space and time. It doesn’t make universe limited in any way, though.
CSP
And if it wasn’t enough, one of the most prominent Go features – built-in concurrency based on the CSP (Communicating Sequential Processes) theory – also, unsurprisingly, plays exceptionally well with our brains. On its surface, CSP is kinda simple thing – it gives you two main concepts to learn: processes and channels (“goroutines” and “channels” in Go). And that is so easy to relate to the physical world and understand intuitively!
Anything that behaves without your involvement – “in the background” – can be a goroutine. And any way you interact – communicate – with it, can be expressed as a channel. You naturally can see concurrency patterns everywhere:
- you’re doing public speaking – fan out
- cashier taking money from customers and putting into the drawer – fan in
- you’re sending and receiving text messages – multiplexing via select{}
- and so on.
Compare this to models like async/await and Futures – you return objects of type Future, that will “resolve” sometime in the future. It just doesn’t make sense in the real world, and it’s ridiculously hard to work with after Go concurrency – it simply doesn’t map onto our mental models easily.
Go as mapping tool
When I read random Go code, I virtually always can quickly answer the question about any code part – why is it there? What exactly does it represent? Is it essential or accidental complexity? What did the author try to say with this part?
Don’t get me wrong – there is a lot of Go code that is, umm, not good, but the problem is mostly with mental maps it encodes, not with the encoding itself.
In bad Go code, the problem is mostly with mental maps it encodes, not with the encoding itself.
I write Go full-time for almost 6 years now, and I still enjoy it the same way as in first months. It definitely made programming fun again for me.
But, oh, that 90% frustrating code text reading part…
Idea of visualization
That’s where dots got connected, and I thought – “okay, Go makes this spatial decoding process ridiculously straightforward and natural for the brain”. Maybe even so straightforward that I can capture them, formalize and offload this task to the computer? Computers are good and processing large chunks of texts, after all, and brains are good at extracting patterns from the data, so perhaps I can marry my frustration of code text reading with my love of Go simplicity and power of visualizations?
So I started first by capturing basic principles of how my mental spatial pseudo-visual representation of the code looks like. Here some basic principles:
Packages
Packages in Go are the central logical units of abstraction. They usually represent large pieces of abstraction, vastly different from each other. Go differs from most mainstream programming languages in the meaning of directories. Other languages tend to use directory just for namespacing things, and it’s basically a workaround for dealing filesystem – and it has little to do with the structure of problem domain per se. In Go, each directory is a package – a logical unit – and I really like this, because it makes it simpler to build high-level spatial links just by seeing directory tree.
Package with subpackages (now called “Go module” since Go 1.11) is a logical unit and I see it as a set of graph nodes with connections to sub-packages. Being a subpackage doesn’t mean it’s actually used in this package, so it’s easy to make the wrong assumption (imagine obsolete subpackage that survived refactoring and stays in version control for years, because everyone assumes it’s used), and I have to resolve this discrepancy in my mind upon reading the code.

Concrete Types
Concrete types – mostly structures – are the most important tool Go gives you to represent anything, physical or ephemeral. “Color”, “Planet”, “Mood”, “Time” – any concept you might think about as a separate abstraction is a candidate for concrete type in your code. So easy.
That’s where, I think, people who ask “why can’t I add my method to the basic types like string?” are missing the point. If you have to modify behaviour of string – it’s likely not a string anymore, and you have to capture that difference not by adding a new method, but by creating a new type (like type UUID string) that does all you need and represents your UUID, and not a general string.
I see types also as nodes that connected to the package they belong. Types that have fields of other types from the same package I see also as nodes to connected to each other. Interesting, but at this point, I don’t care if it’s just a type or a pointer to a type or even embedding – it just captures the relationship. Embedding is a particularly curious concept – it works well when type structure and methods are hidden (say, in another package), so human.Speak() makes more sense than, say, human.mouth.Speak(), but if embedding is used in the same package, I still keep in my mental map that Speak() is the method of Mouth type, not of Human, hence there is an only syntactical win, not the cognitive one.

Functions/methods
In a nutshell, a method is just a function with a first argument being a type, so they’re very similar to me. But logically, the method is always tied to the type (receiver), and I see this as a connected node with a type node. If one method calls another one, that second is likely to be closer to its caller (especially if there are no other callers and/or it’s private).
Same for functions – they’re linked if they call each other, and I think their size does matter (the more lines of code, the bigger the node). I don’t go deeper than that – technically you can define types (including anonymous types) and closures inside a function, but it doesn’t stick to my mind, and I definitely don’t keep that mental image around when navigating code.
That’s interesting, but I top-down order seems to matter – packages are always on top, then types and first-order functions, then methods and all the nested/linked stuff. It’s probably because of the omnipresent concept of the gravity that really influence our intuition even for such abstract things as mental maps.

Interfaces
Interfaces stand out from the rest of code blocks – they generalize behaviour and do it implicitly. In a way, they capture common functionality of seemingly unrelated things in the context of this particular problem.
Being implicit makes interfaces such a powerful tool for expressing reality in a code! The same type can be used in a myriad of different contexts, without knowing them upfront. I can’t imagine returning to the languages where type forced to declare which interfaces it implements, and after Go experience, it’s hard to believe many languages still do that.
In Go, you don’t create interfaces before you have at least two types to generalize upon – it’s just doesn’t make sense. In my head, I see interface kinda like a cloud around type nodes that implement it, which brings them closer, forming a group in a way. It gives flexibility to that internal spatial map, because each type can implement many interfaces used in this particular code, and I’m interested mostly in capturing the meaning of interface and what other types implement it.

Names
Names, as I said before, are crucial for establishing links to mental maps, and they convey a lot of meaning. Conventionally special names like NewFoo() usually represent constructor functions, so I see them linked and closer to the type node. Semantically related name pairs like Start/Stop or Push/Pop are definitely close to each other in my head, and same prefixes/suffixes – like LightTheme/DarkTheme or ServerTCP/ServerUDP – also tend to cluster together in my head.

So that’s just some of the examples of those “rules”. I don’t think I figured out them all, but that should give you a rough idea of what I’m trying to do.
Tool preview
That’s what I’m trying to do – read Go code, parse it, and build a 3D map of spatial relationships of main code concepts, as close as possible to how I do it in my head anyway. Whenever I can’t break down code further into the nodes to visualize – just display functions text, so I can read and fill in the temporal aspect of the code. But 3D visualization should allow me to instantly see what’s this code about, how it’s structured, what entities and abstractions it represents and so on. Instead of red-eyed me, scrolling for half an hour, I’m gently asking a computer to do the dirty job for me, facilitating this mental map decoding and linking process tremendously.
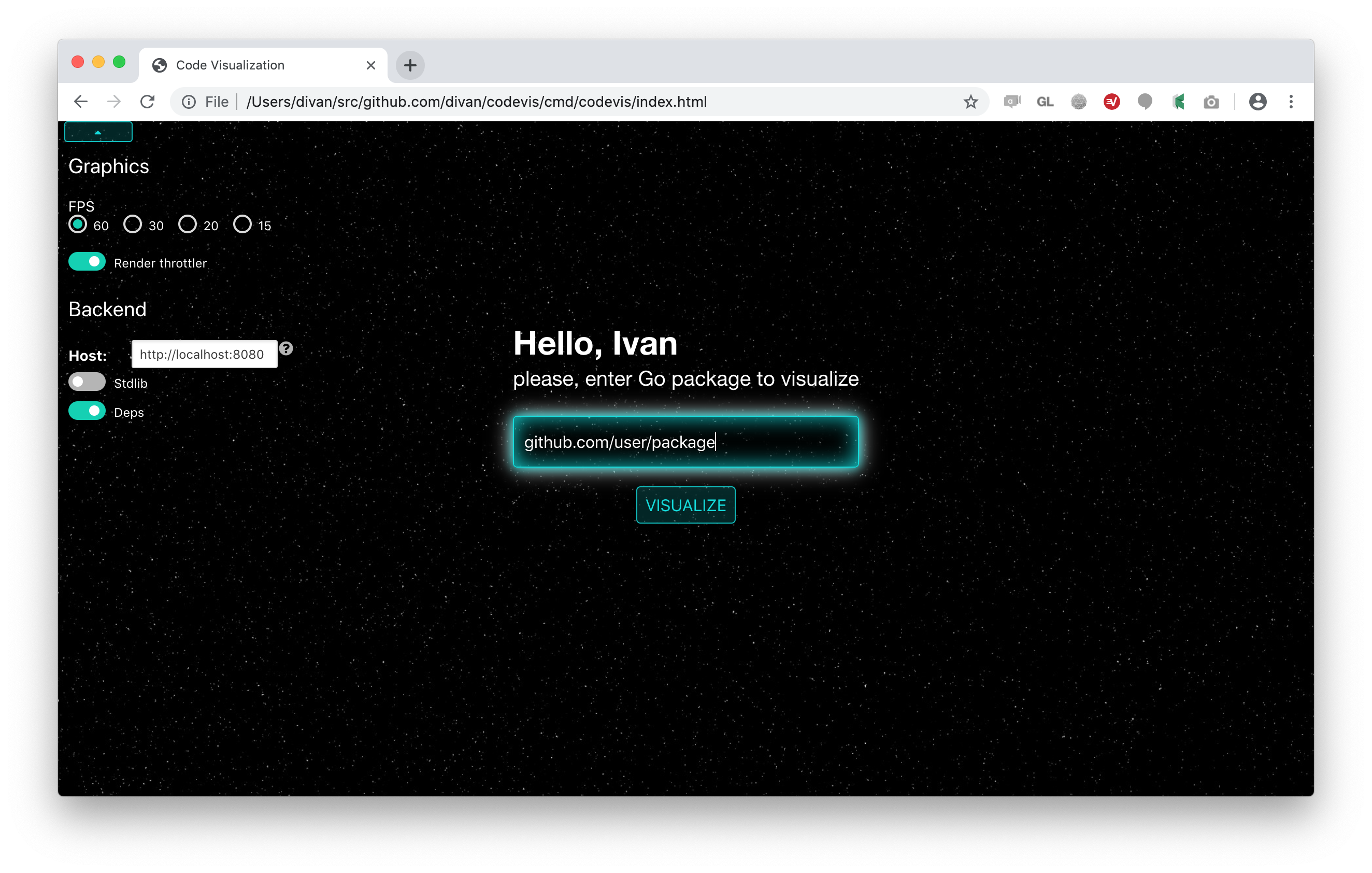
It works in the browser, and talks to the local server just to access the filesystem.
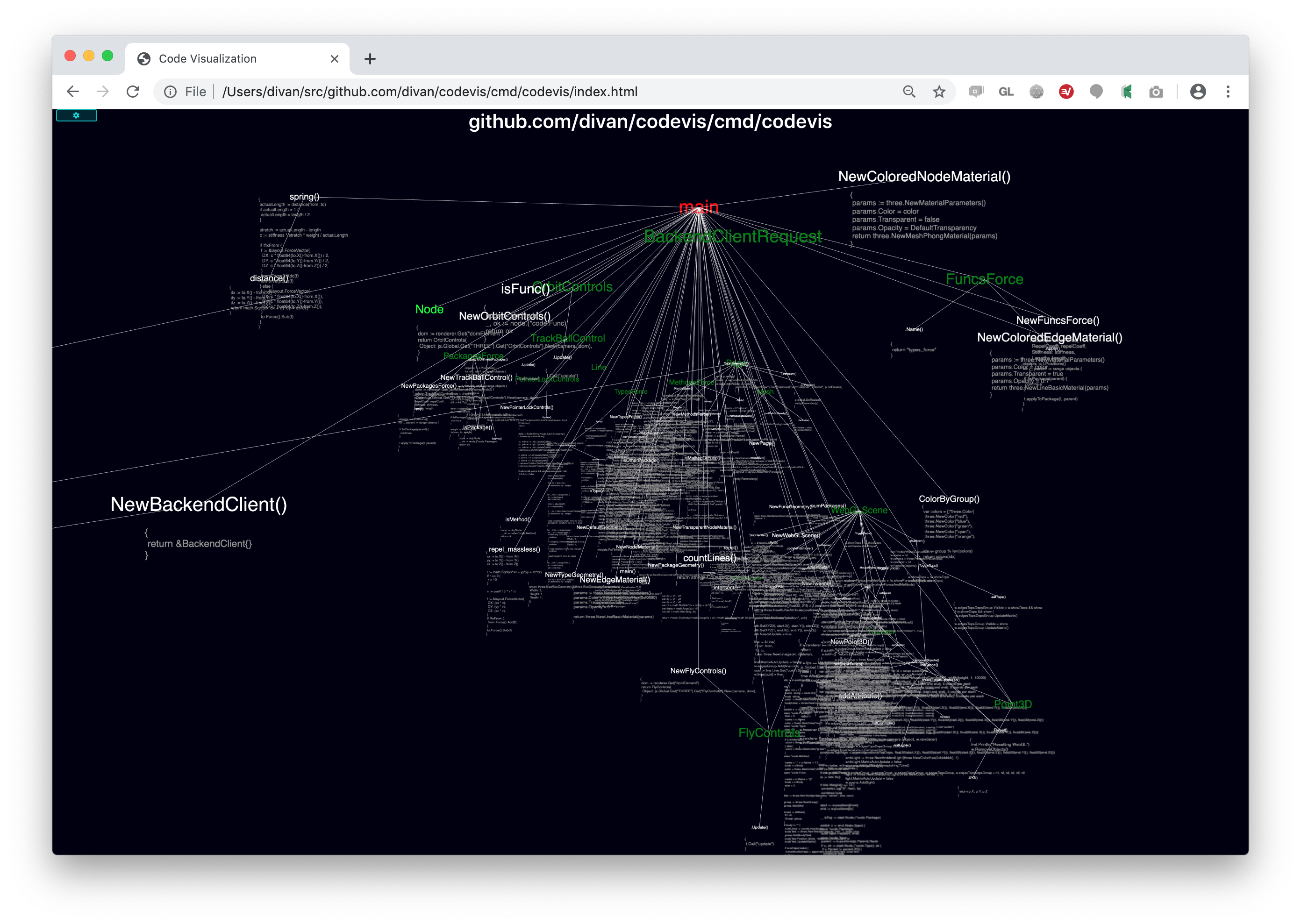
I’m currently at like 20% of what I planned to implement, and while working on it, I go deeper into my head and discover some non-obvious things, which pile up in the backlog. For example, I realized, that I have different zoom levels where I care about different connections – if I’m overviewing a package, I’m interested in one sort of connections, but when I read functions code, I don’t care much about the rest and want more detailization of links coming out of this function.
So, some early previews (small window and low fps, because to save traffic, sorry):
- Intro screen and
container/liststdlib package: - Navigating larger Go package –
github.com/divan/expvarmon:
- Visualizing itself:

- Visualization of package dependencies. With text, adding new dependency is just a single
importline, no matter if it’s a leftpad-like small package or huge 200K LoC elephant. With the visual approach, you’re immediately “feel” the weight of that import line and almost instinctively forced to think twice before using that dependency.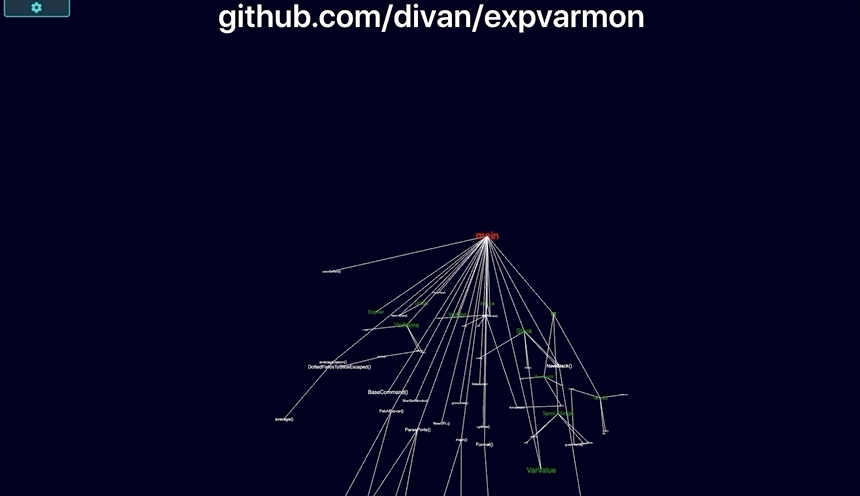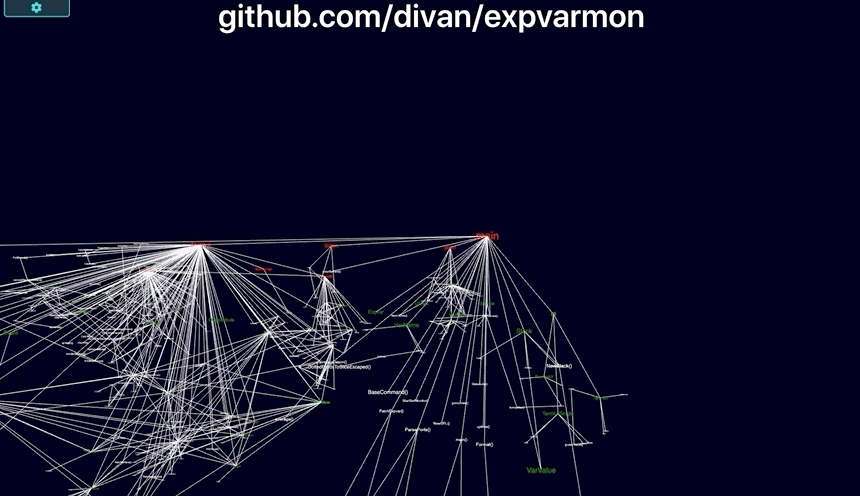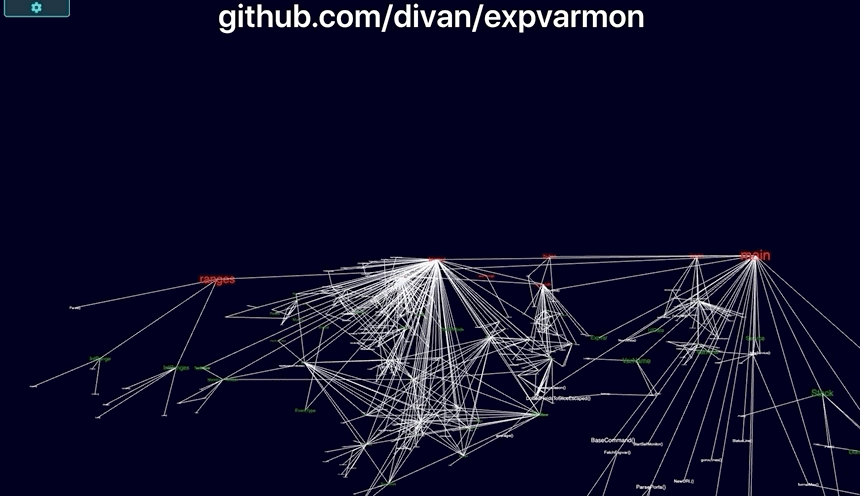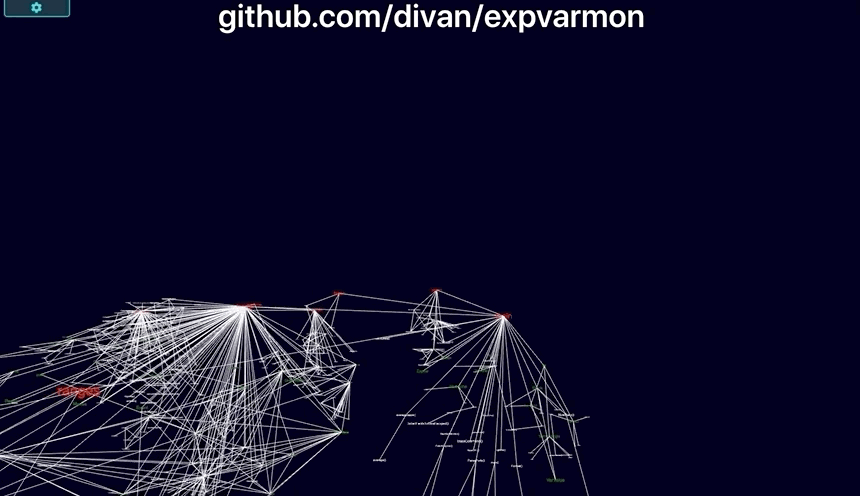
Layout algorithm
I use the force-directed layout approach here, where nodes are placed into 3D space, and then physical forces are applied between them multiple times until the system reaches a stable minimum energy state. Using physics is incredibly important here because it helps with the intuitive aspect of a final layout.
But what’s remarkable is that most of the force-directed algorithms try to produce an aesthetically pleasing graph for any kind of data. However, in my case, I want the opposite – I want it to produce beautiful layout only for good code and yield crappy picture for a terrible code.
The reasoning here is simple: first, it works this way in my head anyway, so I stick to it – the bad code looks messy in my head (and that’s why it’s hard to work with overcomplicated code), and second, I want this aspect to be visible on purpose. Instead of learning rules of good code like “we can’t keep more than 7 objects in short term memory, so keep abstractions small” let visualization speak for itself and intuition to do the job.
Notes
Some random notes on this approach.
- First, it’s not a call graph. This graph captures some interfunctional relations, but it’s very different from being a call graph, and that’s not what you see when you open pprof output, for example.
- Visualizations of code structure do exist for other languages as well, and I’ve seen some really cool projects, especially for Java. But they fundamentally differ in two aspects:
- Their main purpose is to help navigate in an insane maze of class hierarchies and accidental complexity
- Visualizing classes as nodes doesn’t really help for building spatial relationships map, for the reasons I explained earlier – class represent everything and nothing at the same time.
- So this approach to code visualization makes sense only because of the Go’s design simplicity. I can imagine building similar visualization for other languages but I don’t see how they can represent mental maps as good as Go. Less is more.
- Tool is written is written in Go, using GopherJS and Vecty framework for web-based UIs in Go. It renders 3D scene with WebGL using GopherJS wrapper for Three.js, though.
- I’m not sure if I want or not to get rid of files. Splitting code text in chunks and naming them can help for logically grouping things, but it’s so easy to loose synchronization between files names and actual things they supposed to group. At some point filesystem layer starts creating more harm to mental map-to-code linking process than good. Currently, I don’t care about how code is laid out on the filesystem.
- In my head I don’t use colors for “nodes”, because, uhm, it’s not actually visual image in the head – I’m not synesthetic person or anything. It’s just our mental map is built upon same neurological “hardware” as visual cortex, and both deal with a lot of spatial information, so they “feel” similar. And that’s great, because color is such a powerful tool if used right – with color we can quickly visualize different aspects of code:
- Nodes’ children – coloring nested trees of types/methods/functions can improve navigation and understanding
- Public/private API – if position in the space doesn’t show this clearly, color might help.
- Color different kinds of nodes – types/funcs/interfaces/etc – what I do for now, helps to differentiate objects.
- Pprof/cover output
- Especially I’d love to have visual representation of the diffs in pull-requests, but that’s for the future.
Status
This project is a complete experiment I’m working on it in my free time, and it’s in early alpha stage and doesn’t even have a name (internally I just use “codevis” – code visualization). Experiment means it absolutely can fail for tons of reasons, but what will matter is that lessons learned from this experiment. I’m using so many subjective assumptions here, and it’s the first time I’m even sharing all those ideas with anyone, so maybe it works totally different for other people. I would be happy if it’d work just for me, though.
My goal now is to shift to a dogfooding stage and use this tool to work on itself. I’m going to experiment with two options – editing code right inside the browser and talking to the editor in another window via WebSocket.
One of the major challenges I have is a 3D programming itself, which I have little experience with. We’re in 2019, and it’s still hard to efficiently draw text in 3D or draw a thousand lines without making your CPU burn or using optimizations that stop code from being self-explanatory, unfortunately. Also, I spent a lot of time figuring out the physics, as tuning parameters for the forces between nodes is almost dark magic. It’s surprising how bad our brains work with physics where constants are different from the real world ones – one small change and the whole world goes bananas, plus it should work well for both small graphs and large ones, which makes it even more complicated.
Even in this early stage, I kinda enjoy the result. It’s so encouraging to go get a random project, open it with this tool and immediately see it’s structure and be able to navigate the codebase using “wasd” keys, like in good old Quake I days. At least, I feel like I’m on the right track now.
It’s still not ready for open-sourcing, but that’s just a matter of time – as soon as I’m sure it works reliably for basic cases, I’m definitely going to open it.
Future
Also, I would love to get rid of windows and screens completely at some point and use this 3D code representation in the AR environment. Latest demos from Hololens 2 team give me hope that we’re not far from the screen killing moment (i.e. with sufficiently high resolution you can render any screen you want on your retina, so they become obsolete), and the latest price announcements from NReal shows that the market is growing and prices are getting lower for the AR devices.

I would definitely love to be able to physically walk to the part of the code I’m interested in, or pull it closer with hands. I find it unfortunate that programming almost locks you in the sitting position. So the transition to visual programming can slightly change the game here.
Conclusions
In the late sixties, at the first NATO Software Engineering Conference in Garmisch the term “software crisis” has been coined. The rapid increase of the computing power made it obvious that current methods of writing software are insufficient, but new methods haven’t been invented yet.
I think nowadays we’re having another crisis where scale of codebases doesn’t not match tooling we have to deal with it. The complexity of the problems we’re solving didn’t grow too much, though – making UI with sidebar and three buttons unlikely to compete with Apollo mission code – but the complexity of the languages and tooling we use have become orders of magnitude bigger and keep growing.
I feel like this fire torch problem contributes a lot to it. It’s so easy to overlook the impact your code makes onto the overall code structure, when you see just a tiny part of it, lit up by your editor. Seeing those changes instantly and being able to use spatial power of our brain to navigate the code should not only bring a natural incentive to write simpler and better structured code, but perhaps can shift conventional understanding of the programming, from packers’ mindset of “applying patterns” to the mappers’ one of “building maps”.
We shape our tools, and thereafter our tools shape us.
Feedback
I’m genuinely interested in the feedback, negative or positive. If you’re into this topic, please let me know your thoughts and ideas. I’m a bit both excited and terrified to publish this post, as I never showed this project before and, in a way, I’m giving a sneak peek into my head, which is creepy :)
However, I’d love to connect more with folks thinking in a similar direction and see flaws in my logic (especially from neuroscientists – feel free to rebuke my layman vision of the topic).
If you like this project, you may buy me a coffee, and I would definitely be glad to devote more time to work on this project.
Contacts
Twitter: @idanyliuk
Github: https://github.com/divan